Linux 进程管理之完全公平调度器 (CFS)
这篇文章是学习 Linux 目前采用的完全公平进程调度器的笔记,基于 Linux 内核 5.15.146 版本。
进程调度的演进
Linux 的调度器前后出现过三个:
- O(n) 调度器(内核版本 2.4-2.6)
- O(1) 调度器(内核版本 2.6.0-2.6.22)
- CFS 调度器(内核版本 2.6.23-至今)
O(n) 调度器
O(n) 调度器会比较就绪队列中的动态优先级最高的进程作为下一个调度进程。进程被分配固定的时间片,时间片用完后,调度器调度下一个进程。用于存放就绪进程的队列称为 runqueue,在各个 CPU 之间共享,如下所示:
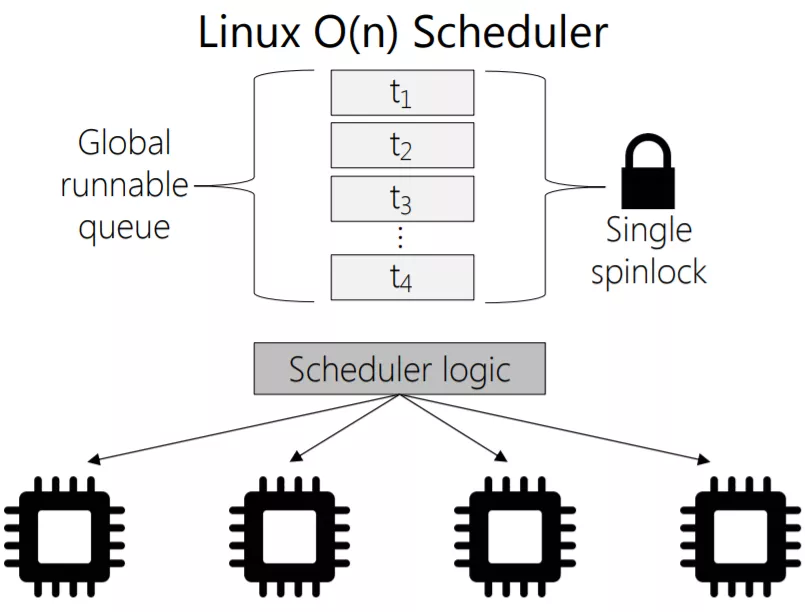
它存在如下问题:
- 每次调度进程都要遍历 runqueue,时间复杂度为 O(n)。
- 多个 CPU 共享全局队列,增删进程的加锁开销较大。
- 实时进程和普通进程混合且无序存放,实时进程无法及时调度。
- 无法让进程更多在同一个 CPU 上执行。
O(1) 调度器
O(1) 最大的变化是让每个 CPU 维护一个 runqueue,减少锁的竞争。每一个 runqueue 运行队列维护两个数组,一个是 active 数组,运行中的进程都挂载 active 数组的某个链表上;一个是 expired 数组,所有时间片用完的进程都挂载 expired 数组的某个链表上。当 acitve 中无进程可运行时,说明系统中所有进程的时间片都已经耗光,应该进入到下一个调度周期,这时候则只需要调整 active 和 expired 的指针即可。
在 Linux 中,始终使用 0-139 这 140 个数字表示进程的优先级。O(1) 调度器 runqueue 中的两个数组长度皆为 140,分别指向不同优先级的进程组成的链表。其中,前 100 个优先级链表属于实时进程,后 40 个属于普通进程。O(1) 使用一个 bitmap 获取最高优先级的可运行进程,时间复杂度是 O(1)。
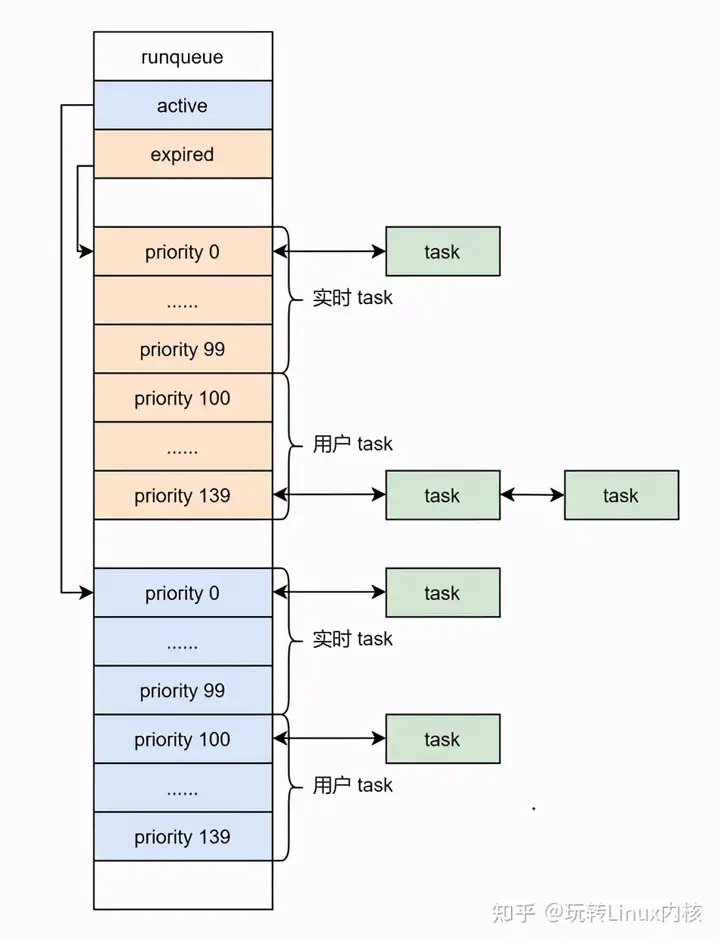
说到进程优先级,在用户空间,Linux 提供了一个函数来调整优先级:
1
2
#include <unistd.h>
int nice(int inc);
这里的参数被称为 nice 值,它越小优先级越高,取值范围 [-20, 19]。nice 值到进程优先级的转换非常简单,[-20, 19] 的 nice 值分别对应 [100, 139] 的优先级。在内核中,转换由宏 NICE_TO_PRIO 完成。
以上讲的是进程的静态优先级,O(1) 调度器会根据进程是交互式进程还是 CPU-bound 进程,减小优先级数值(进行奖励,最多减 5),或增加优先级数值(进行惩罚,最多加 5),形成动态优先级。交互式进程更容易被赋予高优先级,而 CPU-bound 与之相反。
CPU-bound 即 CPU 密集型,表示该进程执行进度取决于处理器速度。与之相对的,交互式进程又被称为 IO-bound 进程。
O(1) 调度器通过一种启发式的方法来检测进程是哪种类型,它会统计进程休眠时间减去运行时间的差值,差值越大,越可能是交互式进程,越容易被提高优先级。
O(1) 的主要问题是当 runqueue 中有大量交互式进程时,CPU-bound 进程会出现饥饿。交互式一般会被赋予较高的优先级,进而抢占 CPU-bound 进程。
O(1) 问题的具体原因暂时没有时间看,相关资料有 On the Fairness of Linux O(1) Scheduler。
CFS 调度器
接下来介绍 Linux 内核目前采用的完全公平调度器 (Completely Fair Scheduler, CFS)。
进程优先级
Linux 中优先级用一个数值表示,数值越大,优先级越低。优先级值的划分如下:
- 普通进程:100~139
- 实时进程:0~99
- deadline 进程:-1
Linux 还有一个用来表示普通进程优先级的 nice 值,它的范围是 -20~19,映射为优先级数值的 100~139。也就是说,在普通进程中,nice 值为 -20 的优先级最高,为 19 的优先级最低。
在 Linux 中,优先级数值 (priority value) 越小优先级 (priority) 越高,注意区分用语。
glibc 提供一个函数来修改当前进程的 nice 值:
1
2
#include <unistd.h>
int nice(int inc); // 新 nice 值 = 旧 nice 值 + inc,并作为返回值返回
除了 nice 函数外,glibc 还提供了给指定 PID、指定 PGID、指定 UID 的所有进程设置 nice 值的 API:
1
2
3
4
#include <sys/resource.h>
int getpriority(int which, id_t who);
int setpriority(int which, id_t who, int prio); // which 指示类型,who 给出 ID,prio 表示 nice 值
调度类和调度策略
Linux 内核将调度策略 (scheduler policy) 抽象为调度类 (scheduler class)。我们可以将一个调度类理解为只调度特定类型进程的调度器,而调度策略是调度器可以采用的调度算法。目前,Linux 内一共有 5 个这样的调度类,每个调度类有零到多个调度策略:
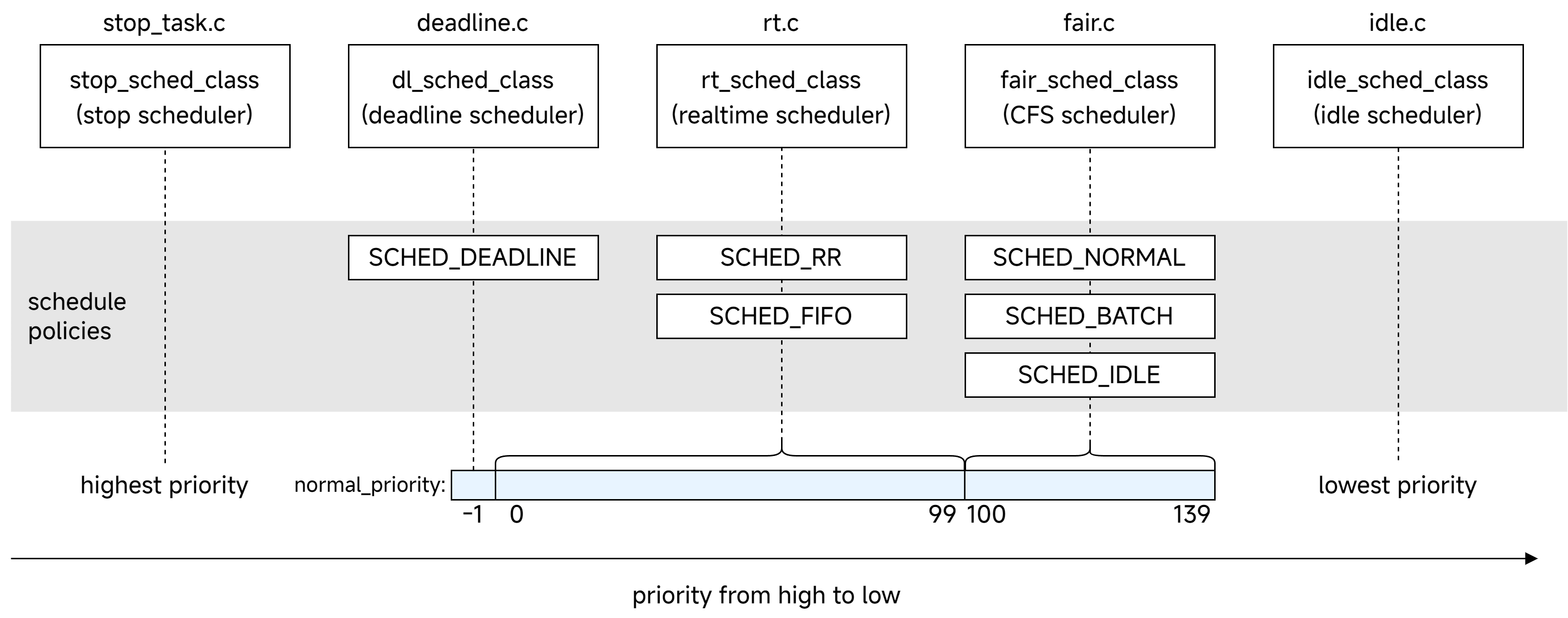
不同调度类的调度对象如下表所示:
| 调度类 | 使用范围 | 说明 |
|---|---|---|
| stop | 最高优先级的进程 | 调度每 CPU 一个的特殊内核线程,它可以抢占任何进程,用于特殊用途,比如 CPU 热插拔 |
| deadline | 最高优先级的实时进程,优先级数值为 -1 | 用于调度有严格时间要求的实时进程,如视频编/译码等 |
| realtime | 普通实时进程,优先级数值为 0~99 | 用于普通的实时进程,如 IRQ 线程化 |
| CFS | 普通进程,优先级数值为 100~139 | |
| idle | 最低优先级的 idle 内核线程 | 没有就绪进程时进入 idle 类,调度每 CPU 的 idle 线程,以节约 CPU 资源(执行 hlt 指令) |
更高优先级的调度类中的进程可以抢占更低优先级调度类中的进程。调度类可用的调度策略有:
- deadline 调度类:SCHED_DEADLINE
- realtime 调度类:SCHED_FIFO, SCHED_RR
- CFS 调度类:SCHED_NORMAL (SCHED_OTHER), SCHED_BATCH, SCHED_IDLE
每个调度策略具体含义可以参考手册。进程所采用的调度策略和实时进程的优先级可以用如下 glibc API 进行修改:
1
2
3
4
#include <sched.h>
int sched_setscheduler(pid_t pid, int policy, // policy 指定调度策略
const struct sched_param *param); // param 中可以设置实时进程的优先级
int sched_getscheduler(pid_t pid);
除此之外,还有更强大的系统调用 sched_setattr 可以使用。
目前 task_struct 中与调度相关的成员
目前需要关注的 task_struct 中与调度相关的成员有:
1
2
3
4
5
6
7
8
9
10
11
12
13
struct task_struct {
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
struct sched_dl_entity dl;
unsigned int policy;
};
sched_class 即前面所讲的调度类,它是一个类似于 file_operations 的接口类,内部成员全都是函数指针。policy 指明当前使用的调度策略,经常被用来判断进程属于哪种类型。se, rt, dl 分别是普通进程、实时进程、deadline 进程所用的调度实体。
优先级相关的成员:
prio: 动态优先级,会动态调整。使用effective_prio()内核函数的返回值初始化,在 realtime 调度策略下,保持 prio 不变,其他策略下赋值为 normal_prio。static_prio: 静态优先级,数值范围 [100,139],只在 CFS 调度类中有意义,除了在进程创建时初始化,还可以由nice()等用户态接口修改。normal_prio: 标准化优先级,对实时进程和普通进程都有意义的统一优先级,数值范围 [-1,139]。rt_priority: 实时进程优先级,数值范围 [1,99],该数值越低优先级越低,和标准化优先级是相反的,[1,99] 一一映射到标准化优先级的 [98,0]。即计算方式是:normal_prio = 100 - 1 - rt_priority。
为什么 rt_priority 如此特殊?在系统调用 sched_setattr 的参数中,sched_attr 结构体指定了调度策略和优先级等信息。如下所示,其中 sched_nice 用于设置普通进程的优先级。而 sched_priority 用于设置实时进程的优先级,它的范围恰好是 [1,99],值越小优先级越低,在内核中对应 rt_priority。这个取值范围也可以通过 sched_get_priority_min() 和 sched_get_priority_max() 用户态接口得到。
1
2
3
4
5
6
7
8
struct sched_attr {
u32 size; /* Size of this structure */
u32 sched_policy; /* Policy (SCHED_*) */
u64 sched_flags; /* Flags */
s32 sched_nice; /* Nice value (SCHED_OTHER, SCHED_BATCH) */
u32 sched_priority; /* Static priority (SCHED_FIFO, SCHED_RR) */
...
}
虚拟时间 (vruntime)
接下来进入到 CFS 部分。CFS 引入了一个重要概念:虚拟时间 (vruntime),与真实时间相对。CFS 规定,nice 为 0 的进程,虚拟时间流逝的速度与真实时间相同。进程优先级越高,权重越大,该进程的虚拟时间流逝得更慢。
在 CFS 所使用的调度实体 struct sched_entity 中,成员 load 保存了该实体的权重,该结构体的定义是:
1
2
3
4
5
// include/linux/sched.h
struct load_weight {
unsigned long weight;
u32 inv_weight;
};
优先级越高,权重值 weight 越大。内核预先定义了一个常量数组 sched_prio_to_weight[40],使用 nice+20 作为下标可以获得对应权重值,当 nice 值等于 0 时,权重为 1024。
inv_weight 是为了方便虚拟时间的计算所设置的,它的计算方式如下:
\[\text{inv_weight} = \frac{2^{32}}{\text{weight}}\]内核也提供了常量数组 sched_prio_to_wmult[40] 用于快速获取 inv_weight。有了 inv_weight,可以快速计算虚拟时间:
其中,dealta_exec 是真实时间,nice_0_weight 是 nice 值为 0 时的权重值,可见权重越大,vruntime 增长得越慢。这部分计算逻辑在函数 calc_delta_fair() 中。
就绪队列 rq 和 cfs_rq
struct rq 是通用就绪队列,包含了 CFS 就绪队列 cfs_rq、实时进程就绪队列 rt_rq、deadline 进程就绪队列 dl_rq,以及负载权重信息等。rq 是一个 per-CPU 变量,即每个 CPU 都有一个 rq 结构体。cfs_rq, rt_rq, dl_rq 都不是指针成员,因此也都是每 CPU 一份。
rq 相关的结构体关系如下图所示:
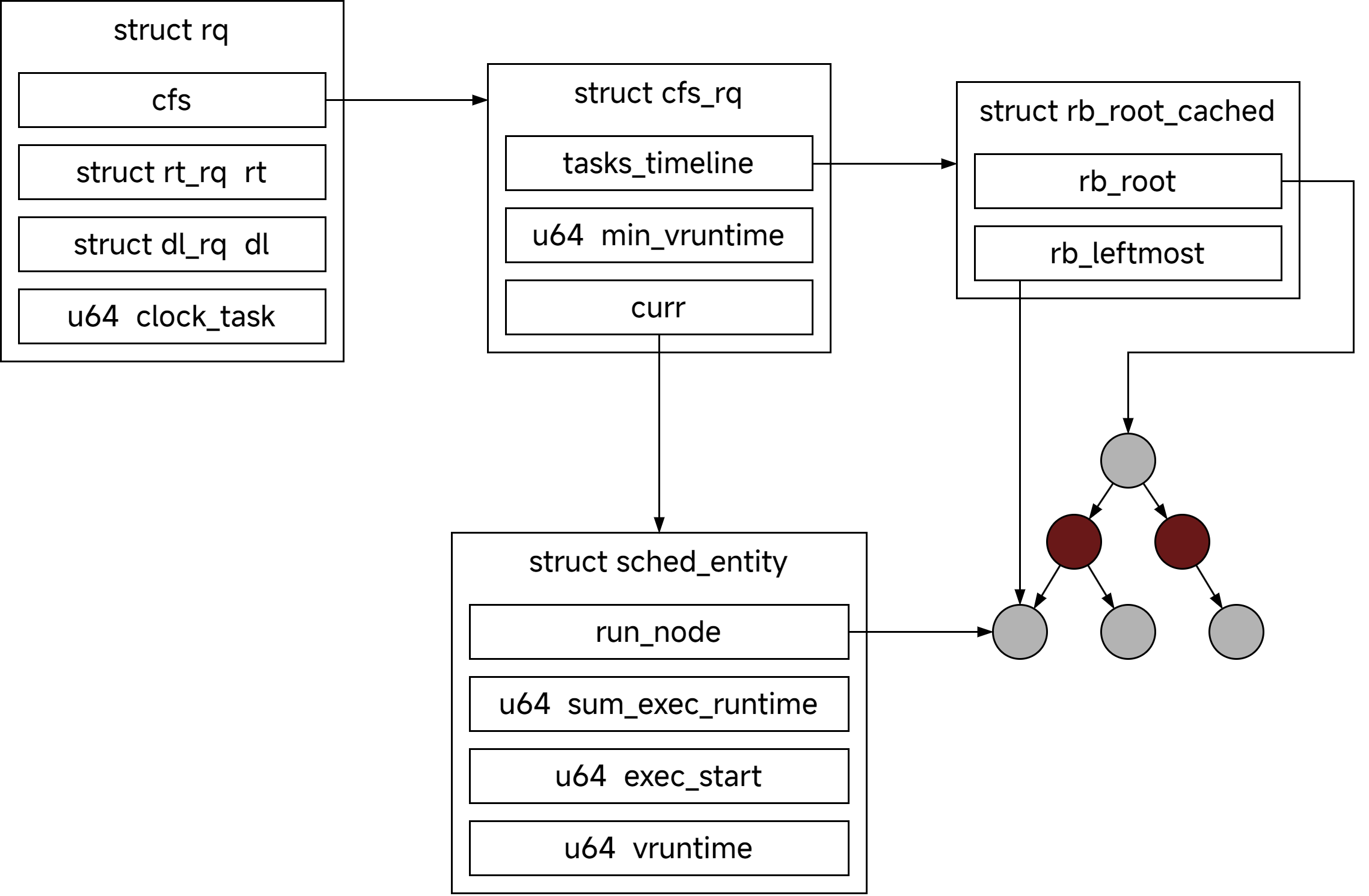
可以看到,cfs_rq 维护了一个调度实体组成的红黑树,按照虚拟时间排序,最左边的节点就是虚拟时间最小的调度实体。
进程的创建
进程创建流程如下:
1
2
3
4
5
kernel_clone()
├copy_process()
│ ├sched_fork()
│ └sched_cgroup_fork()
└wake_up_new_task()
sched_fork() 进行了调度类设置等初始化工作。在 sched_cgroup_fork() 里面需要关注的是调度类的 task_fork() 接口。CFS 调度类的 task_fork() 简化版本如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
static void task_fork_fair(struct task_struct *p)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se, *curr;
struct rq *rq = this_rq();
struct rq_flags rf;
rq_lock(rq, &rf);
update_rq_clock(rq);
cfs_rq = task_cfs_rq(current);
curr = cfs_rq->curr;
if (curr) {
update_curr(cfs_rq);
se->vruntime = curr->vruntime;
}
place_entity(cfs_rq, se, 1);
se->vruntime -= cfs_rq->min_vruntime;
rq_unlock(rq, &rf);
}
Note1: 进程创建时,子进程 vruntime 等于 max(父进程的 vruntime, min_vruntime + 惩罚)。 Note2: 较老版本的内核是 child run first,现在是 parent run first。
这里的 cfs_rq->curr 指向的当前运行进程也就是父进程,p 表示正在创建的子进程。该函数首先调用 update_curr 更新了 cfs_rq->curr 的虚拟时间,然后赋给了子进程。place_entity() 则根据情况对子进程虚拟时间进行一些惩罚。最后,子进程的虚拟时间减去了 min_vruntime,这是因为它还没有进入就绪队列。当它进入就绪队列时,会再加上 min_vruntime,这样做是为了消除这段时间 cfs_rq 的 min_vruntime 发生变化带来的影响。
update_curr 函数
update_curr 用来更新当前运行进程的虚拟时间,它简化代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = cfs_rq->rq->clock_task;
u64 delta_exec;
delta_exec = now - curr->exec_start;
curr->exec_start = now;
curr->sum_exec_runtime += delta_exec;
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
}
可以看到,它用到我们前面讲的用于计算虚拟时间的函数 calc_delta_fair,这里用于计算的真实时间就是当前时间减去执行开始时间,即 cfs_rq->rq->clock_task - cfs_rq->curr->exec_start。最后,该函数还更新了就绪队列的最小虚拟时间。
惩罚子进程虚拟时间
place_entity 有两个用途,这里用到的是惩罚子进程虚拟时间的逻辑,它的简化代码如下:
1
2
3
4
5
6
7
8
static void place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
{
u64 vruntime = cfs_rq->min_vruntime;
if (initial && sched_feat(START_DEBIT))
vruntime += sched_vslice(cfs_rq, se);
...
se->vruntime = max_vruntime(se->vruntime, vruntime);
}
可见惩罚并不是在原来的 se->vruntime(这种情况下等于父进程 vruntime)的基础上进行的,而是在队列的 min_vruntime 上进行的。最后 vruntime 取了 se->vruntime 和 min_vruntime + penalty 的较大值。
惩罚值的计算是 sched_vslice(),它的代码只有一行:
1
return calc_delta_fair(sched_slice(cfs_rq, se), se);
用于惩罚的真实时间是由 sched_slice(cfs_rq, se) 计算得到,它的简化代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
unsigned int nr_running = cfs_rq->nr_running;
u64 slice;
slice = __sched_period(nr_running + !se->on_rq);
struct load_weight *load;
struct load_weight lw;
cfs_rq = cfs_rq_of(se);
load = &cfs_rq->load;
if (unlikely(!se->on_rq)) { // 当前情况下,该子进程还未放到就绪队列,所以进入 if
lw = cfs_rq->load;
update_load_add(&lw, se->load.weight);
load = &lw;
}
slice = __calc_delta(slice, se->load.weight, load);
return slice;
}
首先,__sched_period 会计算一个调度周期的时间长度。默认为 6ms (sysctl_sched_latency),当就绪进程数量大于 8 时,调度周期等于就绪数量乘以 0.75ms。然后该函数会计算按照权重占比,当前 se 在调度周期所占得的分片长度,__calc_delta 实际上做出了如下计算:
加入调度器
完成创建新进程的大部分工作后,需要调用 wake_up_new_task() 将进程添加到调度器中。这部分工作包括设置进程状态为 TASK_RUNNING、调用调度类的 enqueue_task() 将调度实体加入到 CFS 调度类、设置p->on_rq 为 TASK_ON_RQ_QUEUED 等。
CFS 调度类的 enqueue_task() 包括了把 min_vruntime 加回来、添加调度实体到红黑树等工作。以上这部分的调用关系如下:
1
2
3
4
5
6
7
kernel_clone()
└wake_up_new_task()
└activate_task()
└enqueue_task() // core.c
└enqueue_task_fair() // fair.c
└enqueue_entity()
└__enqueue_entity() // 添加红黑树节点
进程的调度
__schedule() 函数是进程调度的核心函数。它的注释给出了调度的时机:
- 阻塞操作:mutex, semaphore, waitqueue 等等。
- 在中断返回前和系统调用返回用户空间时,检查 TIF_NEED_RESCHED 标志位以判断是否需要调度。
- 将要被唤醒的进程不会马上调用
schedule(),而是会被添加到 CFS 就绪队列中。如果它要抢占当前进程,就会设置 TIF_NEED_RESCHED,然后schedule()在合适的时机被调用。什么是“合适时机”这里就不展开了。
TIF_NEED_RESCHED 标志位在当前进程描述符的
thread_info->flags成员中设置,获取和设置都很方便。
我们这里只关心 CFS 是如何挑选下一个执行的进程的,抽取相关代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
static void __sched notrace __schedule(unsigned int sched_mode)
{
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
next = pick_next_task(rq, prev, &rf);
if (likely(prev != next)) {
rq = context_switch(rq, prev, next, &rf);
}
}
pick_next_task() 封装了对 __pick_next_task() 的调用。__pick_next_task() 做了一个小优化,如果当前进程 prev 的调度类是 CFS 调度类,并且该 CPU 整个就绪队列中的进程数量等于 CFS 就绪队列中进程数量,则直接调用 CFS 的 pick_next_task_fair() 函数,否则按优先顺序遍历调用各调度类的 pick_next_task() 接口。
在 pick_next_task_fair() 中,最关键的就是 pick_next_entity(),它选择了下一个执行的调度实体。简化代码如下:
1
2
3
4
5
6
7
8
static struct sched_entity *
pick_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
struct sched_entity *left = __pick_first_entity(cfs_rq);
struct sched_entity *se;
if (!left || (curr && entity_before(curr, left)))
left = curr;
}
简言之,最终选择的调度实体一般就是红黑树最左边的节点。
这里的 entity_before() 非常有意思,它的定义如下:
1
2
3
4
5
static inline bool entity_before(struct sched_entity *a,
struct sched_entity *b)
{
return (s64)(a->vruntime - b->vruntime) < 0;
}
我们知道虚拟时间的类型是 u64。如果随着时间推进,vruntime 出现了 wrap around 现象怎么办?一个进程的 vruntime 突然从很大变成很小,这是我们不能接受的。内核采用上面所示的方式避免该问题,首先将结果转成带符号的 s64,通过结果的符号比较谁更大。而且只要两个 vruntime 的真实差距没有超过数轴的一半,该结果的符号就不会反转。
唤醒的进程
有一些进程因为等待 I/O 事件等原因进入了睡眠状态,在它回到就绪状态前,它的 vruntime 都没有更新过,会非常小。内核不可能因此将大量 CPU 时间分配给这种进程,所以需要重新设置这种进程的 vruntime。
在 enqueue_entity() 内,如果发现进程是被唤醒的,就会调用 place_entity() 对它的 vruntime 进行补偿。这就是 place_entity() 的第二个作用。
1
2
3
4
5
6
7
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
...
if (flags & ENQUEUE_WAKEUP)
place_entity(cfs_rq, se, 0);
}
place_entity() 的代码如下,可以看到
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
static void
place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
{
u64 vruntime = cfs_rq->min_vruntime;
//...惩罚 vruntime 的代码略
if (!initial) {
unsigned long thresh = sysctl_sched_latency;
if (sched_feat(GENTLE_FAIR_SLEEPERS))
thresh >>= 1;
vruntime -= thresh;
}
if (entity_is_long_sleeper(se))
se->vruntime = vruntime;
else
se->vruntime = max_vruntime(se->vruntime, vruntime);
}
由于采用的基准值是 cfs_rq->min_vruntime,因此最后该进程的 vruntime 一定不会落后就绪队列其他进程 vruntime 太多。并且,内核还会对唤醒进程进行补偿,即在 cfs_rq->min_vruntime 的基础上适当减少它的虚拟时间。
传统的补偿方式 (GENTLE_FAIR_SLEEPERS 为 false) 下, 补偿值用 sysctl_sched_latency (即调度周期)。相当于比就绪队列上其他进程落后一个调度周期。但是直接将虚拟运行时间下调一个调度周期,将导致该进程与其他进程的虚拟运行时间相差太大,长时间占有 CPU。因此如果 GENTLE_FAIR_SLEEPERS 特性开启,将补偿值下调为原来的一半,即 sysctl_sched_latency >>= 1。
通常情况下,由于睡眠导致未更新 se->vruntime,max_vruntime(se->vruntime, vruntime) 的结果都是 vruntime。但如果该进程睡眠了很长时间,se->vruntime 与 min_vruntime 的比较结果可能会导致 s64 溢出,从而使结果反转。内核在这里做了保护性检查,当它发现进程睡眠很长时间时,直接忽略原来的 se->vruntime。
时钟调度
每当时钟中断发生时,Linux 调度器的 scheduler_tick() 函数会被调用,执行和调度相关的一些操作。该函数会调用 update_rq_clock(),后者更新 rq->clock_task,其在 update_curr() 中被用来指示当前的真实时刻。
然后,scheduler_tick() 会调用调度类的 task_tick() 函数。CFS 调度器的实现为 task_tick_fair()。task_tick_fair() 会对当前执行的进程调用 entity_tick()。这部分调用关系如下:
1
2
3
4
5
6
scheduler_tick()
├update_rq_clock()
└task_tick_fair()
└entity_tick()
├update_curr()
└check_preempt_tick()
entity_tick() 首先会更新当前执行进程的 vruntime,然后调用 check_preempt_tick() 尝试抢占当前执行的进程。这部分简化代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
ideal_runtime = sched_slice(cfs_rq, curr);
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
if (delta_exec > ideal_runtime) {
resched_curr(rq_of(cfs_rq));
clear_buddies(cfs_rq, curr);
return;
}
if (delta_exec < sysctl_sched_min_granularity)
return;
se = __pick_first_entity(cfs_rq);
delta = curr->vruntime - se->vruntime;
if (delta < 0)
return;
if (delta > ideal_runtime)
resched_curr(rq_of(cfs_rq));
}
分析如下:
- ideal_runtime 是通过
sched_slice()计算出当前进程在一个时钟周期分得的真实时间分片长度。计算方式之前已经讲解过了。 - delta_exec 是实际运行时长,如果实际运行时间已经超过了理论运行时间 ideal_runtime,那么当前进程就应该被抢占。
resched_curr()函数设置当前进程 thread_info 中的 TIF_NEED_RESCHED 标志位。 - 如果该进程实际运行时间小于 sysctl_sched_min_granularity(最小抢占粒度,默认为 0.75ms),则它不需要被调度。
- 如果该进程 vruntime 减去红黑树最左侧 vruntime 的差值比理论运行时间还大,则触发调度。
这里最关键的是实际运行时间和理论运行时间的比较,它确保一个进程不会一直执行下去。注意,这里比较的是真实时间。一个权重大的进程,在调度周期中分得真实时间分片更多,同时虚拟时间过得更慢,此消彼长,队列中进程的 vruntime 不会拉开差距,而是以相同的速率增长。
总之,scheduler_tick() 并不会导致调度直接发生,而是当判断需要调度时,设置当前进程的 TIF_NEED_RESCHED 标志位。实际的调度依旧在之前所说的 3 个时机发生。
参考资料
- 玩转Linux内核进程调度,这一篇就够(所有的知识点)
- Linux内核CFS调度器:实现高效多任务处理
- On the Fairness of Linux O(1) Scheduler
- 奔跑吧 Linux 内核(第2版)卷1:基础架构
- Linux内核与设备驱动程序学习笔记
Comments