论文阅读:Sub-Operators
本文是对论文 Database Technology for the Masses: Sub-Operators as First-Class Entities 的翻译和解释。
动机
数据库提供了独特的功能,例如强大的声明性语言、高级编译和优化技术以及实现高吞吐率的基本技术。它们还提供一致性、可用性和可恢复性保证。然而,越来越多的用户放弃了传统数据库,以追求灵活性和性能,流行的方案包括直接在 Apache Arrow 这种中间格式上构建,或者使用 Spark 这种分布式计算框架。这往往失去了数据库提供的部分优势,例如强大的一致性、可用性和可恢复性保证,以及优化器。
作者认为,传统数据库没有理由不能支持更灵活的数据访问和处理方式。他们建议利用围绕数据库引擎开发的概念来实现创新,从而提供灵活性和传统上与数据库相关的优势。他们强调了重用现有技术的潜力,例如算子模型、编译技术、算子可组合性和正交性以及优化和调度技术。然而,为了获得更大的灵活性,需要改变数据库引擎接口的显式抽象级别。
Sub-Operator 的优势
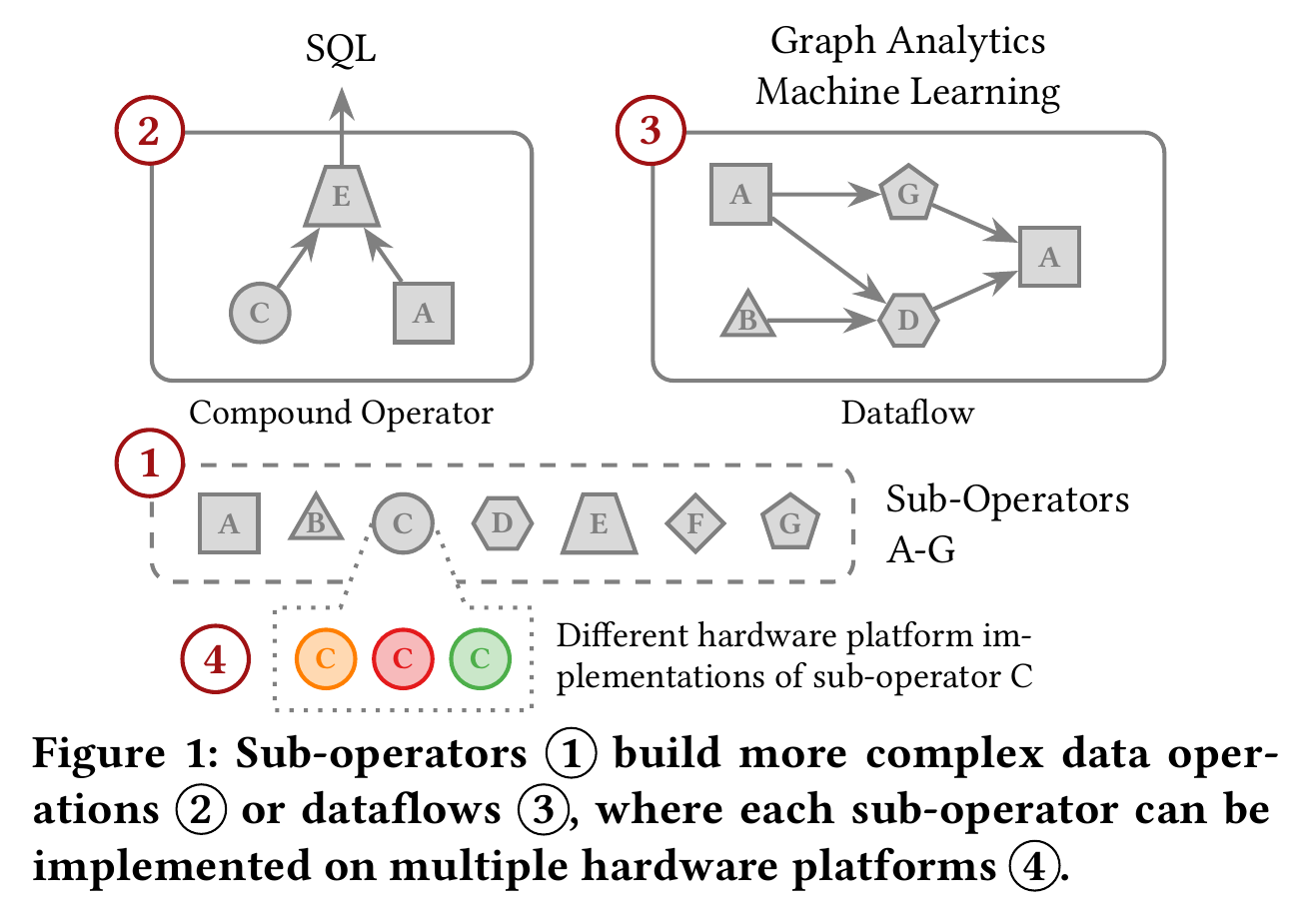
作者提出使用 Sub-Operators 作为执行基本数据转换和管理任务的逻辑函数。通过在子操作符级别公开接口,作者建议将传统数据库引擎转变为能够处理的不仅仅是 SQL 的语言运行时引擎 (language runtime engine)。这扩展了数据库的能力以适应不同的数据流,例如机器学习和图计算。
使用子操作符作为各种数据流的通用构建块,来构建复杂的数据流,可以将工作流的逻辑推理与硬件的实现细节分开。而且,这简化了代码库维护,特别是在面对多样化且快速发展的硬件环境,比如云中的资源分离时。启用备选的子操作符实现有助于不同硬件平台 (CPU, GPU, FPGA) 的混合程序的交叉编译。
作者还强调了在子操作符上下文中重用现有技术的潜力,例如算子模型、编译技术以及优化和调度技术。这种重用允许高效建模、分析并将子操作符合并到查询优化器中,而不会牺牲性能。
与当前涉及用户定义函数 (UDF) 或 table functions 的方法相比,子操作符为用户提供了定制自由度的同时,最大限度地提高系统重用性。作者认为,子操作符类似于处理器中的指令,可供优化器重新排列和编译器根据需要进行组合。相比之下,UDF 则不在优化器的范围之内。
基于 Sub-Operator 的数据库引擎
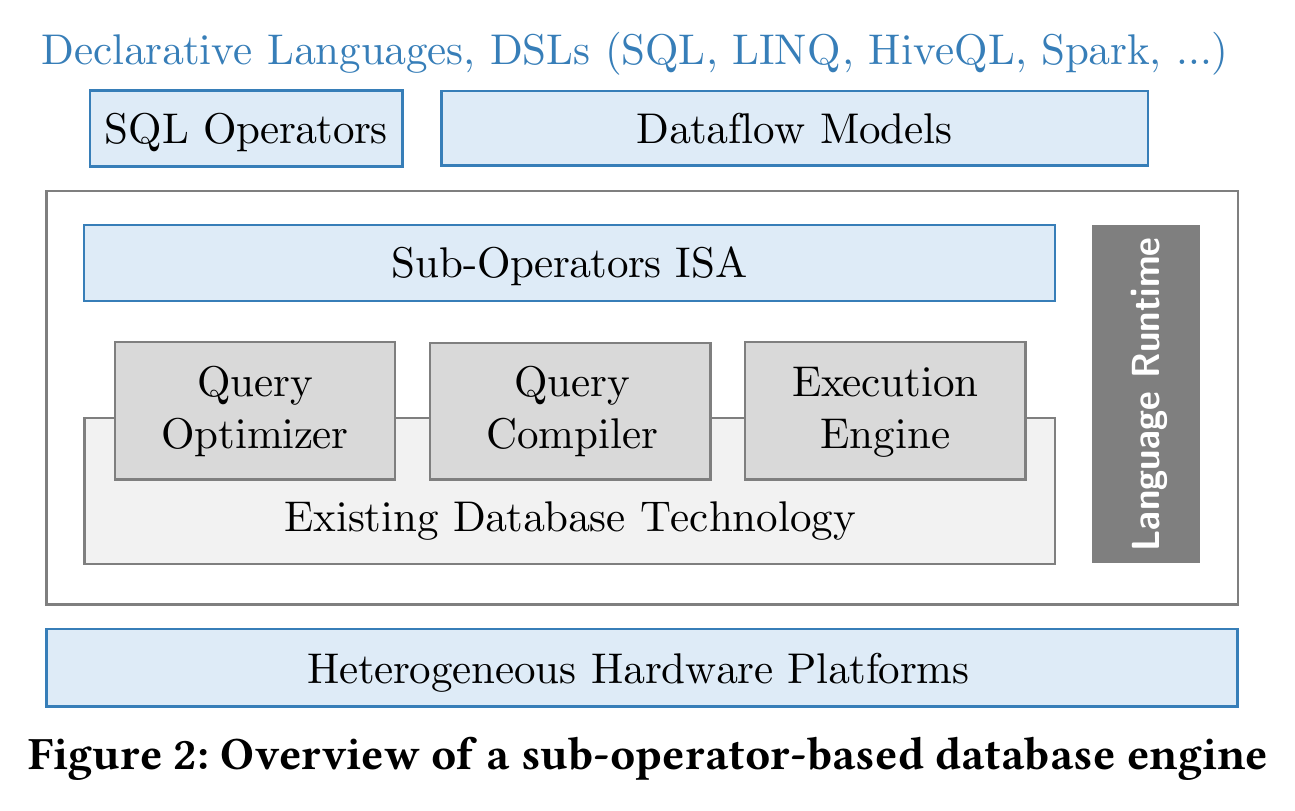
上图是作者设想的基于子操作符的数据库引擎,它将一组子操作符作为接口暴露,将它们组合成更复杂的数据流。可以在其上运行的语言包括 SQL、图处理和机器学习系统中使用的数据流模型。使用子操作符作为 ISA,数据库引擎更像是一个语言运行时,在异构硬件平台上执行一组丰富的备选子操作符实现(作为指令)。它的目标是不仅支持关系型(列和行)数据存储,还支持计算图、键值存储和存储为 blobs 的复杂数据类型的扩展。
Sub-Operators 定义

上图是本文提出的子操作符示例。作者将子操作符分为四类:
- 顺序访问 (Sequential Access):
Scan和Materialize确保系统能够在流式和缓冲执行之间切换。这在处理物化的中间状态或将计算流水线分布到不同的硬件目标时非常重要。 - 随机访问 (Random Access):
Scatter和Gather处理对各种位置的内存访问。它们可以组合实现连接操作。Scatter接收一个元组流,并根据散列函数(比如元组的哈希值)将物化。Gather根据输入流从不同的内存位置获取元组,并将组合的流转发给进一步处理。TODO - 计算 (Compute):
Map和Fold提供对函数式编程原语和典型的 Map-Reduce 工作负载的支持。例如,Map处理一个元组流,并对流中的每个元素应用映射函数 $f$。它可以对不同元组返回不同数量的返回值,包括零个。一个映射函数例子是谓词计算。 - 控制流 (Control Flow):
Loop不属于数据流流水线。它用于控制流程并制定迭代查询,常见于增量和收敛工作负载。
这里使用分区来解释如何将子操作符组合成一个更复杂的子操作符 Partition。
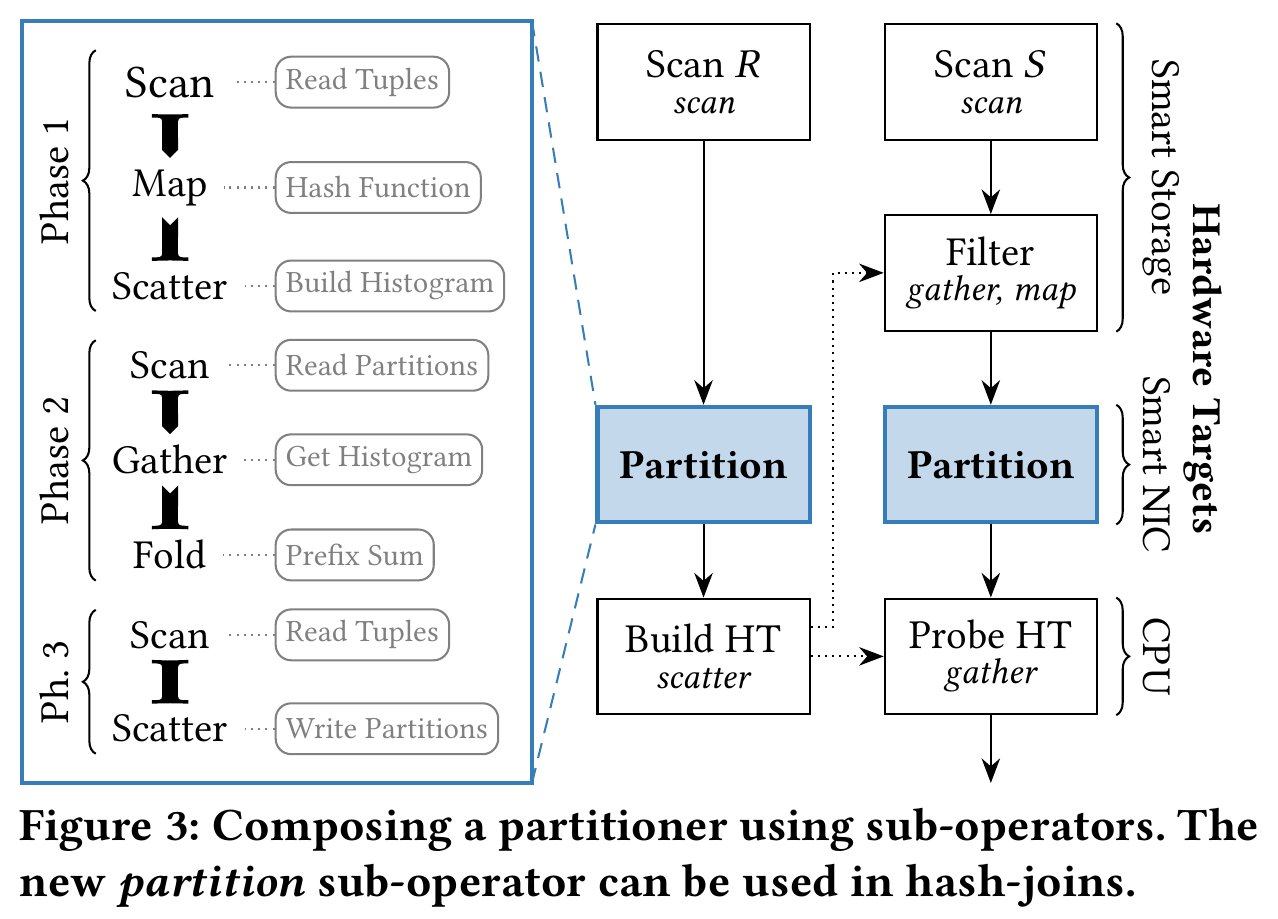
分区包含几个阶段,通常涉及对输入数据进行两次遍历,以实现在流水线系统中的高效并行化:
- 阶段 1 执行第一次扫描,并计算输入元组如何哈希到分区存储桶的直方图。这个阶段使用了
Map(哈希)和Scatter(构建直方图)子操作符来构造。直方图记录元组输出到各哈希桶的数量。 - 在阶段 2 中,每个线程计算前缀和以确定每个分区的跨度。为此,它使用
Scan来读取分区并使用Gather来检索直方图。然后,Fold子操作符计算前缀和以确定每个线程需要写入其元组份额的偏移量。 - 最后一个阶段对输入数据进行第二次遍历,并将元组
Scatter到预先计算的位置。
一旦构建完成,新的分区子操作符可以作为其他关系运算符或更复杂的数据流的构建模块使用。
如上图右侧所示,数据流逐渐从读取存储转变为计算,这是数据处理工作负载的典型情况。接近存储的工作负载可以通过智能存储加速,而分区则是 FPGA 加速的一个很好的选择,最终的连接逻辑则最适合在 CPU 上运行。在云环境中,这种分布式使用情况对于每个数据系统都非常有吸引力。
为了表示更加复杂的数据流,可以将子操作符作为图的顶点,而边则表示数据依赖和数据如何从一个子操作符移动到另一个子操作符。注意,我们必须保证两侧的子操作符对输入输出的方式是兼容的。输入输出属性可以简单划分为缓冲式 (buffered) 和流式 (streamed) 。这里我们用符号┣ ━ ┫ 来分别替代论文中的三类子操作符的特殊符号。它们的输入输出属性为:
- ┣:输入是缓冲式,输出是流式。例如
Scan,它对一段缓冲区进行顺序扫描。 - ━:输入是流式,输出是流式。例如
Map,它对流中的每个元素应用映射函数,能立即产生一个输出。 - ┫:输入是流式,输出是缓冲式。
Fold,它接收所有元组才能产生结果。Materialize可以将数据流序列化,从而使得数据可以被现有的库或者用户定义代码处理。- 注意,输出是缓冲式并不意味着一定要接收到所有输入,才能产生输出,而是它的输出在生成完毕时才有意义(能被后续处理),比如上图使用到的
Scatter。
- 注意,输出是缓冲式并不意味着一定要接收到所有输入,才能产生输出,而是它的输出在生成完毕时才有意义(能被后续处理),比如上图使用到的
这种定义可以将子操作符组合为流水线 (pipeline)。流水线可以编译为一个函数,能作为一个计算核 (compute kernel) 被执行。这种技术称为算子融合 (operator fusion),它可以将数据尽量维持在寄存器和热缓存中,减少内存访问和数据移动,从而提高性能。
在流式线之间,所物化的缓冲区可以具备一定状态或属性。比如是否按某个属性排序、最大值/最小值、数据分布等等。这些属性用于后续处理和优化。例如,它们可以避免额外的排序操作。
Sub-Operator 的应用
子操作符可以用来组合更强大的关系算子,论文提到的有:
- semi-join reducer: 1, 2
- hash teams operator
- shared operator:
- shared scan: 1, 2
- shared join
- group join: 1, 2
作者希望,子操作符不仅仅用于 SQL,还可以用于多种 DSL,例如:
子操作符还可以用于构建数据挖掘、人工智能等领域的算法,例如 K-means 聚类:
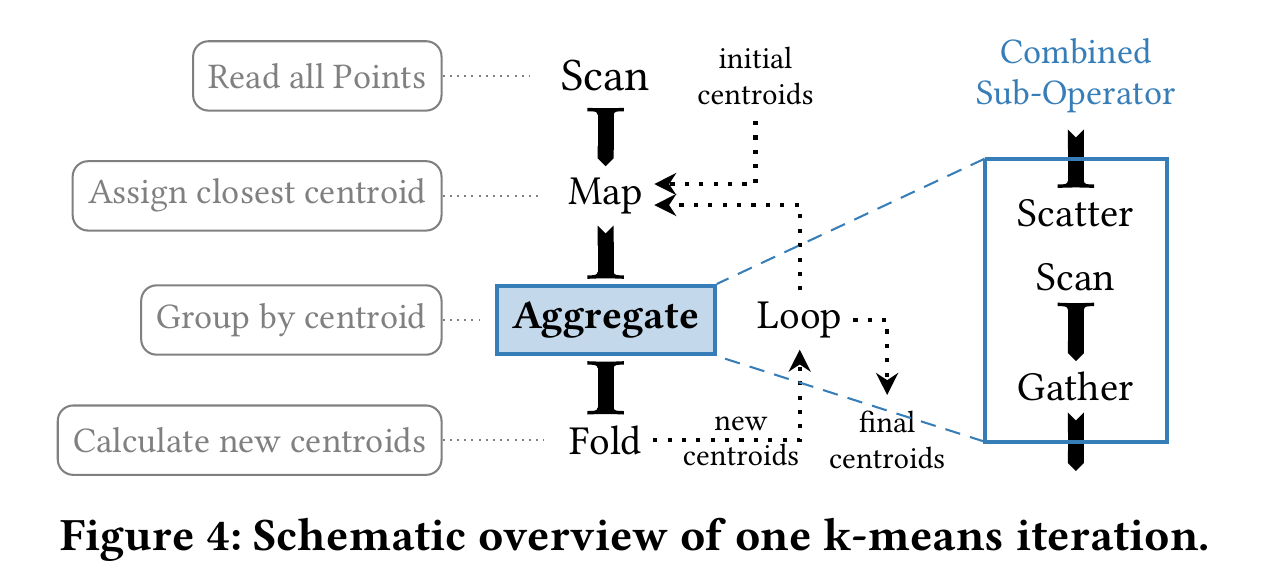
- 首先
Scan所有的数据点,将它们给Map。 Map接收一个数据点,以及当前的所有中心点作为参数,算出最近的中心点。Aggregate算子由多个子操作符组成。它先将数据流映射到最近中心点对应的区域。然后重新开始扫描,最后使用Fold计算新的中心点。- 如果中心点变化,
Loop将新的中心点传递给Map,开启下一轮迭代。否则 K-means 收敛,Loop返回中心点。
接着,作者介绍了子操作符在跨平台编译、硬件电路、异构算力等方面的应用和影响,这里就不细讲了。
Sub-Operator 对数据库引擎的影响
作者在最后一部分介绍了引入子操作符对查询优化、查询编译、执行引擎所产生的影响。
引入子操作符后,查询优化可以分为三个层次:
- High-Level 优化:下降到子操作符之前对高级操作的优化。比如子查询展开、以及给出使用哪种物理算子的提示。
- Mid-Level 优化:该层优化器接收一个数据流图作为输入,将每个关系运算符都被拆解为子操作符。在这里,可以考虑选择哪种物理实现。这意味着我们必须决定是否以及在哪里卸载计算,并由此直接决定如何在所有可用的硬件资源之间划分数据流。此处,成本模型可以重用大量先前的工作,并需要确定如何为不同的硬件平台建模访问模式的成本。
- Low-Level 优化:确定了目标平台后,可以使用 MLIR 将数据流下降到目标平台。此处,可以应用编译器优化如常量传播和自动向量化。(优化范围局限于下降到同一个平台的数据流片段)
作者在这里提到了动态优化,即每个特定平台的子操作符实现可以附加信息,包括执行成本(时间)效率,以及所需的资源(高效执行所需的硬件资源)。优化时,可以使用数据所在的位置以及每个分散的硬件资源当前的负载情况,结合子操作符的辅助信息,做出更加高效的优化。不仅如此,这些信息还可以用于执行引擎的动态调度。
编译这块,作者提到了 pipeline break,这是通过前面提到的子操作符输入输出特性自然而然可以得到的。作者还提及了几个使用编译技术的学术界 DBMS,包括将 Scala 转为 C 的 Legobase,以及使用 LLVM 的 HyPer 和 Umbra。作者最后强调了 MLIR 的重要性。
谈到执行引擎时,作者提到执行器可以缓存相同子操作符的替代实现,并基于优化器建议的偏好,在查询执行过程中动态选择其中之一。如果集成在系统运行时中,执行引擎还可以利用关于异构硬件平台上当前队列长度和各种资源利用情况。可以参考 Vectorwise 的调整技术。
总结
该论文篇幅并不长,只介绍了子操作符的概念,没有相关的实现。实现需要看作者他们基于 MLIR 搭建的 LingoDB 数据库的相关论文:Designing an open framework for query optimization and compilation 和 Declarative Sub-Operators for Universal Data Processing。看完论文,我个人对子操作符的理解还不是很清晰,特别是还无法理解 Gather 子操作符的类型和作用。关于动态优化和动态调用,作者说的比较模糊,有许多疑问并未解决:
- 优化时需要给出偏好的平台并且将高层语言编译为该平台指令吗?还是需要编译所有平台的代码以供调度?
- 任务划分片段的依据是什么?假如一个片段既可以拆分为 CPU 和智能网卡的代码,也可以全部由 CPU 执行。那这个划分是在优化时定死了,还是说可以在执行时发生改变?
- 当执行引擎如果发现其他平台更适合当前任务片段,需要重新编译一次吗?
参考资料
- M. Bandle and J. Giceva, “Database Technology for the Masses: Sub-Operators as First-Class Entities,” Proc. VLDB Endow., vol. 14, no. 11, pp. 2483–2490, Jul. 2021, doi: 10.14778/3476249.3476296.
Comments