论文阅读:Radix Hash Join
本文是对 Main-memory hash joins on multi-core CPUs: Tuning to the underlying hardware 论文 Part II 的翻译和解释。
现有的算法可以分为两种类型:
- 硬件无关 (hardware-oblivious) 的哈希连接,例如无分区连接。硬件无关哈希连接不依赖于任何硬件特定的参数。相反,它们考虑现代硬件的定性特征,并且在任何类似技术的硬件上都能实现良好的性能。
- 硬件感知 (hardware-conscious) 的哈希连接,例如(并行)基数连接,旨在通过调整算法参数(例如哈希表大小)来充分利用给定硬件的特性。
使用第一类连接的假设是硬件现在已经足够好,能够通过自动硬件预取或乱序执行来隐藏自身的限制,从而使硬件无关的算法具有竞争力。使用第二类连接的假设显式参数调整足够带来性能优势,值得付出所需的努力。
经典哈希连接算法
现代哈希连接实现的基础是经典的哈希连接算法,它分为两个阶段,如下图所示。在第一个构建阶段 (build phase) 中,两个输入关系中较小的关系 R 被扫描,以填充一个包含所有 R 元组的哈希表。然后,在探测阶段 (probe phase) 中,扫描第二个输入关系 S,并对每个 S 元组在哈希表中进行探测,以找到匹配的 R 元组。
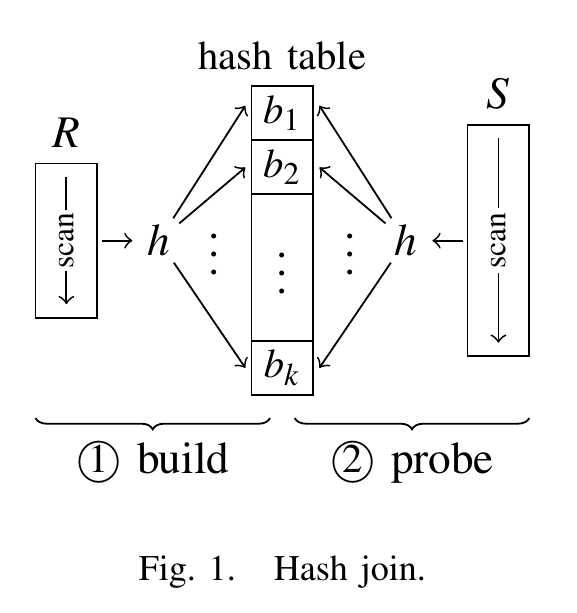
两个输入关系只需扫描一次,并且假设哈希表访问的时间复杂度是常数级别,因此经典哈希连接算法的预期复杂度为 $O(|R|+|S|)$。
无分区连接
为了充分利用现代并行硬件,Blanas 等人提出了一种变体的经典算法,称为无分区连接 (no partitioning join),实质上是经典哈希连接的直接并行版本。它不依赖于任何硬件特定参数,并且与我们即将讨论的其他替代方案不同,它不会对数据进行物理分区。他们的观点是,分区阶段需要对数据进行多次传递,可以通过依赖现代处理器的特性(如同时多线程技术 (SMT))来隐藏缓存延迟,从而省略该阶段。
两个输入关系被分成相等大小的部分,分配给多个工作线程。如下图所示,在构建阶段,所有工作线程都会填充一个共享的哈希表。
构建阶段结束时,所有工作线程同步,一起进入探测阶段,同时为其分配的 S 部分找到匹配的连接元组。
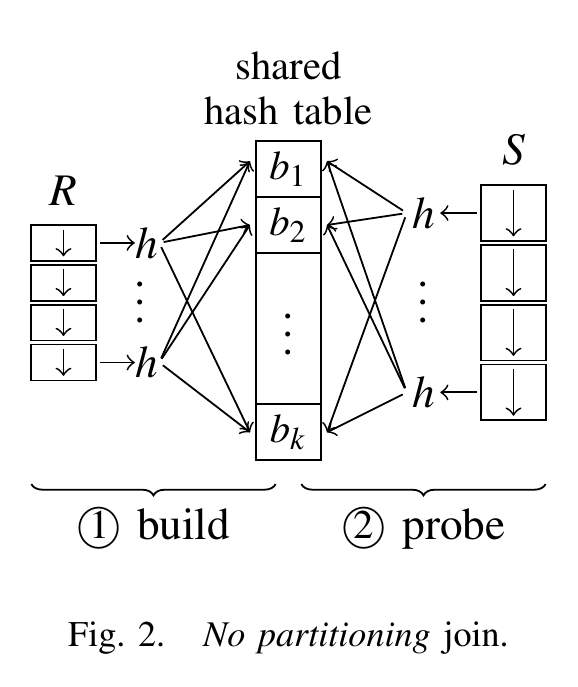
无分区的一个重要特点是哈希表在所有工作线程之间共享。这意味着对哈希表的并发插入必须进行同步。为此,每个桶需要一个锁来保护,线程在插入元组之前必须获取该锁。由于哈希桶的数量通常很大(几百万个),因此潜在的锁争用预计会保持较低水平。在探测阶段,哈希表以只读模式进行访问。因此,在第二阶段不需要获取锁。在具有 $p$ 个核心的系统上,这种哈希连接的并行版本的预期复杂度为 $O(1/p(|R| + |S|))$。
分区与基数连接
硬件感知的主存哈希连接实现是基于 Shatdal 等人和 Manegold 等人的研究结果。尽管哈希的原理——根据键的哈希值进行直接位置访问——很有吸引力,但对内存的随机访问可能导致缓存未命中。因此,主要关注的是通过更有效地使用缓存来调优主存访问,已经证明这会影响查询性能。Shatdal 等人指出,当哈希表大于缓存大小时,几乎每次访问哈希表都会导致缓存未命中。因此,将哈希表分区为与缓存大小相同的块可以减少缓存未命中,并提高性能。Manegold 等人通过考虑在分区阶段的 TLB 的影响,进一步完善了这个想法。这催生了多次分区 (multi-pass partitioning),现在它已成为基数连接算法的标准组成部分。
分区哈希连接
分区的思想下图所示。在算法的第一个阶段中,两个输入关系 R 和 S 分别被划分为分区 $r_i$ 和 $s_j$ 。在构建阶段,为每个 $r_i$ 分区创建一个单独的哈希表(假设 R 是较小的输入关系)。现在,每个哈希表都适合 CPU 缓存。在最后的探测阶段,扫描 $s_j$ 分区,并在相应的哈希表中探测匹配的元组。
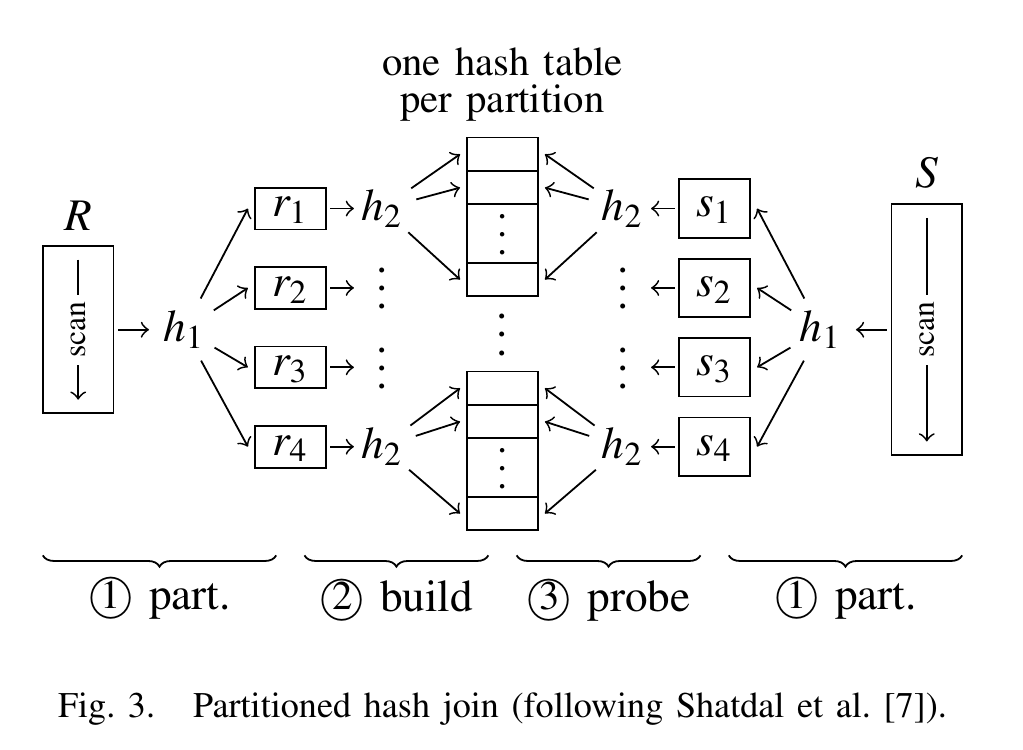
在分区阶段,输入元组使用哈希分区(通过图中的哈希函数 $h_1$)根据它们的键值进行划分($r_i \Join s_j = \varnothing \text{ for } i \ne j$),并使用另一个哈希函数 $h_2$ 填充哈希表。
虽然在构建和探测阶段避免了缓存未命中,但将输入数据分区可能会引发不同类型的缓存问题。分区通常位于不同的内存页面上,每个分区都需要虚拟内存映射的单独条目。 现代处理器的 TLB 缓存了这种映射。正如 Manegold 等人指出的那样,如果创建的分区数量过多,分区阶段可能会导致 TLB 未命中。
实际上,可用的 TLB 条目数量定义了可以同时有效创建或访问的分区数量的上限。
举例说明 TLB 未命中的原因:假设使用 $h_1$ 将输入数据分为 $H$ 个分区,需要将插入位置所处页面虚拟地址转换为物理地址。除非表格非常小,否则插入位置都位于不同的内存页面。这意味着 $H$ 个分区需要 $H$ 个 TLB 条目。插入过程中,$H$ 个内存页面都会被访问,如果 $H$ 大于 TLB 的条目总数量,就会导致 TLB 未命中。
基数分区
可以通过多次分区来避免过多的 TLB 未命中。在每个 pass $j$ 中,通过前一个 pass $j - 1$ 产生的所有分区进行细化,使得分区的扇出不超过由 TLB 条目数量给出的硬件限制。在实践中,每个 pass 依据哈希函数 $h_1$ 输出的不同位集合划分数据,这就是为什么这被称为基数分区 (radix partitioning)。对于典型的内存数据大小,进行两到三次分区就足以创建适合缓存大小的分区,又不会受到 TLB 容量限制的影响。
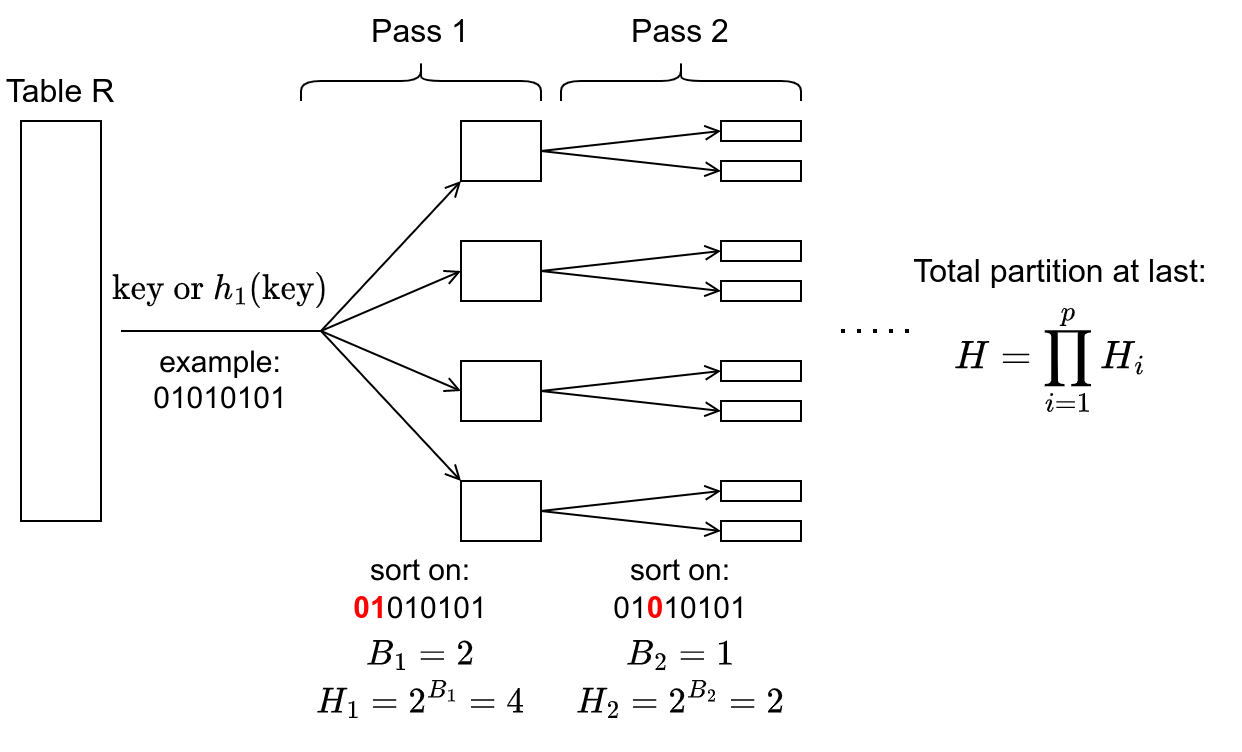
如上图所示,一般使用 $h_1(key)$ 作为分区依据,pass 1 按前两位分区,一份数据产生 4 个分区,pass 2 按第 3 位分区,一份数据产生 2 个分区。在 pass $i$ 中,同时会访问的分区数量为 $H_i$,它由用于分区的位数 $B_i$ 控制。
基数连接
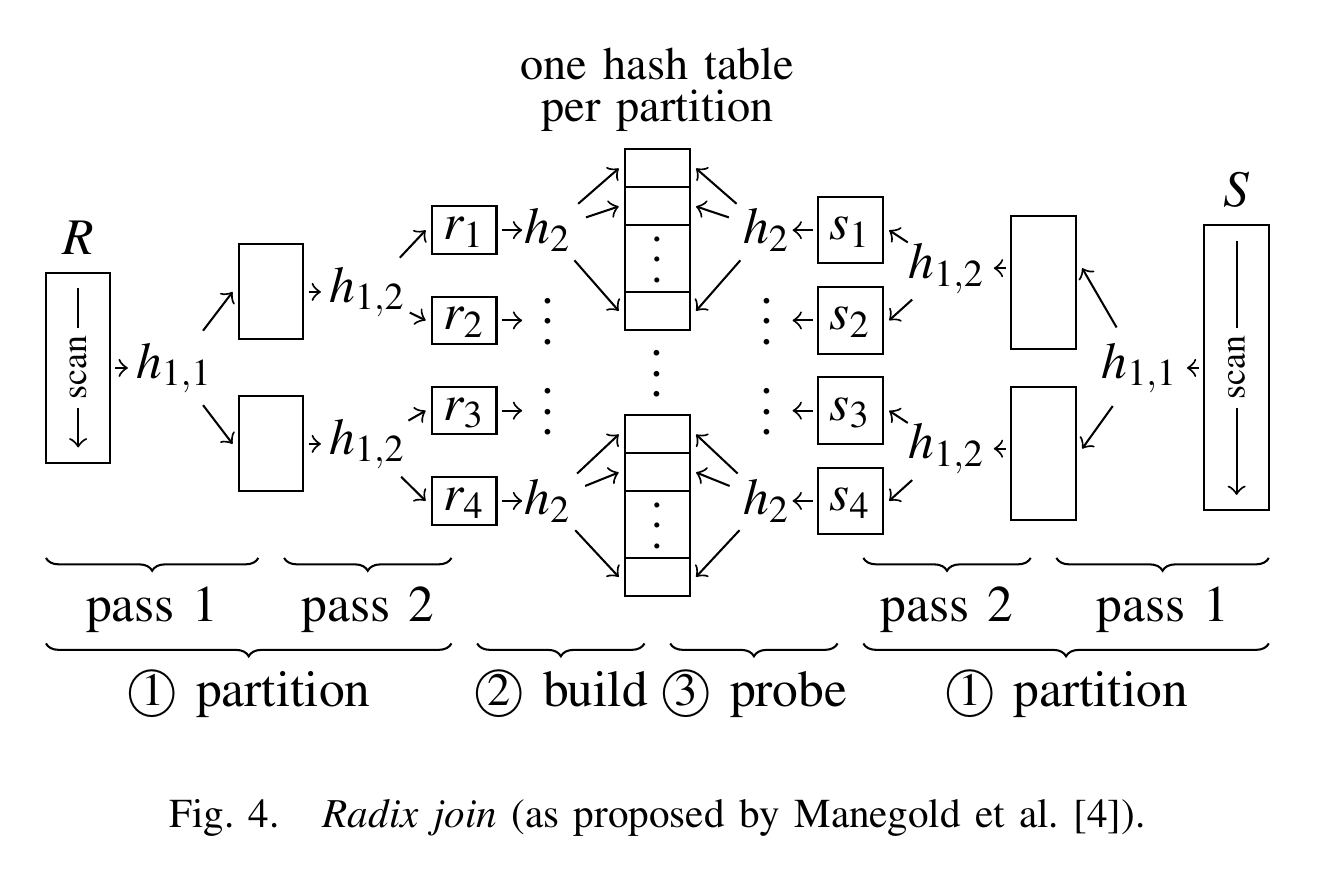
完整的基数连接如下图所示。两个输入关系都使用双 pass 基数分区进行分区(两个 TLB 条目足以支持这个示例)。然后,在输入表 R 的每个 $r_i$ 分区上构建哈希表。最后,扫描所有的 $s_i$ 分区,和对应的 $r_i$ 分区进行连接匹配。
在基数连接中,必须对两个输入关系进行多次遍历。由于每次遍历的最大“扇出”由硬件参数固定,需要进行 $\log|R|$ 次遍历,其中 R 仍然是较小的输入关系。因此,我们预计基数连接的运行时间复杂度为 $O((|R| + |S|) \log |R|)$。
并行基数连接
Kim 等人提出基数连接可以通过将两个输入关系细分为分配给各个线程的子关系来进行并行化。在第一次 pass 中,所有线程创建一个共享的分区集 (shared set of partitions)。与之前一样,这个集合中的分区数量受到硬件参数的限制,通常很小(几十个分区)。它们可以被潜在的多个执行线程访问,从而创建了一个竞争问题(无分区连接的低竞争假设不再适用)。
为了避免这种争用,为每个线程在每个输出分区中预留了一个专用的范围。为此,两个输入关系被扫描两次。第一次扫描计算输入数据的一组直方图,这个直方图记录每个输出分区的预计数量,因此对于每个线程和每个分区,都知道了精确的输出大小。接下来,为输出分配了一个连续的内存空间,并通过计算直方图的前缀和,每个线程预先计算出它写入输出的排他位置。最后,所有线程在没有任何同步需求的情况下执行它们的分区操作。
在第一次分区遍历之后,系统中通常有足够的独立工作,工作线程可以独立执行工作。工作线程之间的负载分配通常通过任务排队来实现。
算法大致流程如下:
- 阶段一:将输入关系平均分为 $\tau$ 个子关系,其中 $\tau$ 是任务数。每个任务维护一个本地直方图 $\text{Hist}_i$,它们遍历子关系,应用哈希函数,计算出 $\text{Hist}_i$。直方图的 key 为哈希值,value 为映射到该哈希值的元组数量。
- 阶段二:考虑第 $j$ 个哈希值,每个任务都记录了映射到第 $j$ 个哈希值的元组数量,将它们相加,也就是 $\sum_{i}\text{Hist}_i[j]$。对于第 $i$ 号任务,它输出 $j$ 哈希值的元组的起始地址为: \(\sum_{k}\sum_{l=0}^{j-1}\text{Hist}_{k}[l] + \sum_{k=0}^{i-1}\text{Hist}_{k}[j]\) 。这个前缀和操作可以使用并行算法。
- 阶段三:每个任务在它的子关系上遍历,使用直方图和相应的输出地址,将元组写入输出分区。
每个阶段结束,线程需要同步。
参考资料
- C. Balkesen, J. Teubner, G. Alonso, and M. T. Özsu, “Main-memory hash joins on multi-core CPUs: Tuning to the underlying hardware,” in 2013 IEEE 29th International Conference on Data Engineering (ICDE), Apr. 2013, pp. 362–373. doi: 10.1109/ICDE.2013.6544839.
- S. Manegold, P. Boncz, and M. Kersten, “Optimizing main-memory join on modern hardware,” IEEE Transactions on Knowledge and Data Engineering, vol. 14, no. 4, pp. 709–730, Jul. 2002, doi: 10.1109/TKDE.2002.1019210.
- C. Kim et al., “Sort vs. Hash revisited: fast join implementation on modern multi-core CPUs,” Proc. VLDB Endow., vol. 2, no. 2, pp. 1378–1389, Aug. 2009, doi: 10.14778/1687553.1687564.
Comments