MPP 是什么?以 Doris 为例
实验室的 OLAP 项目被砍,不知之后是否还有机会再学习 OLAP。我会把这段时间看到的资料整理出来,第一篇就讲讲 MPP 以及分布式优化。本文主要来源于 Doris 在 B 站开设的课程的第四讲和第八讲,该课程是了解 Doris 非常好的资料。
RDBMS 中的并行
在探讨 MPP 和 Doris 前,我们先看 RDBMS 充分利用多核性能的几种并行思路。TiDB 总结的非常好,共有三种主流并行思路:
- Intra operator parallelism: 算子内部并行,需深度定制算子,旨在充分利用单机多核资源。个人认为 radix hash join 就是该思想在 hash join 上的体现。
- Exchange operator: 在算子间加入 exchange 算子,该算子负责切分数据,丢给不同的下游算子实例,以实现并行。对现有算子影响小,可用于跨节点并行。
- Morsel-Driven parallelism: 将表数据划为称为 Morsel 的水平分区,在之上预设并行任务,每核一个 Worker 线程,优先处理数据在本地 NUMA 节点的任务,空闲时可 work stealing。
第二种方式需静态调度,在查询优化时确定每个并行阶段的并行度、数据分发方式,在分布式环境中,执行查询前确定每个查询片段执行的节点。第三种方式则为动态调度——每个 Worker 实际执行的任务是边执行边分配的。
MPP 架构和 exchange 算子密切相关。在单机数据库分布式化的工作中,开发者为了降低系统复杂度,不引入共享资源,采用了 share-nothing/存算一体 的分布式架构——每个节点可看作单机查询引擎,独自管理本机资源。在此架构上形成的分而治之的并行查询方式就是 MPP (Massively Parallel Processing)。每节点的执行器处理本地数据,再通过 exchange 算子将中间结果通过网络发送到下游算子所在节点。
MPP 在 Doris 中的应用
Doris 是一款基于 MPP 架构的开源 OLAP 数据库。我综合了 Doris 的课程视频和文档,结合自己的理解,介绍一下 Doris 中的 MPP 实现。
Doris 的 share-nothing 架构
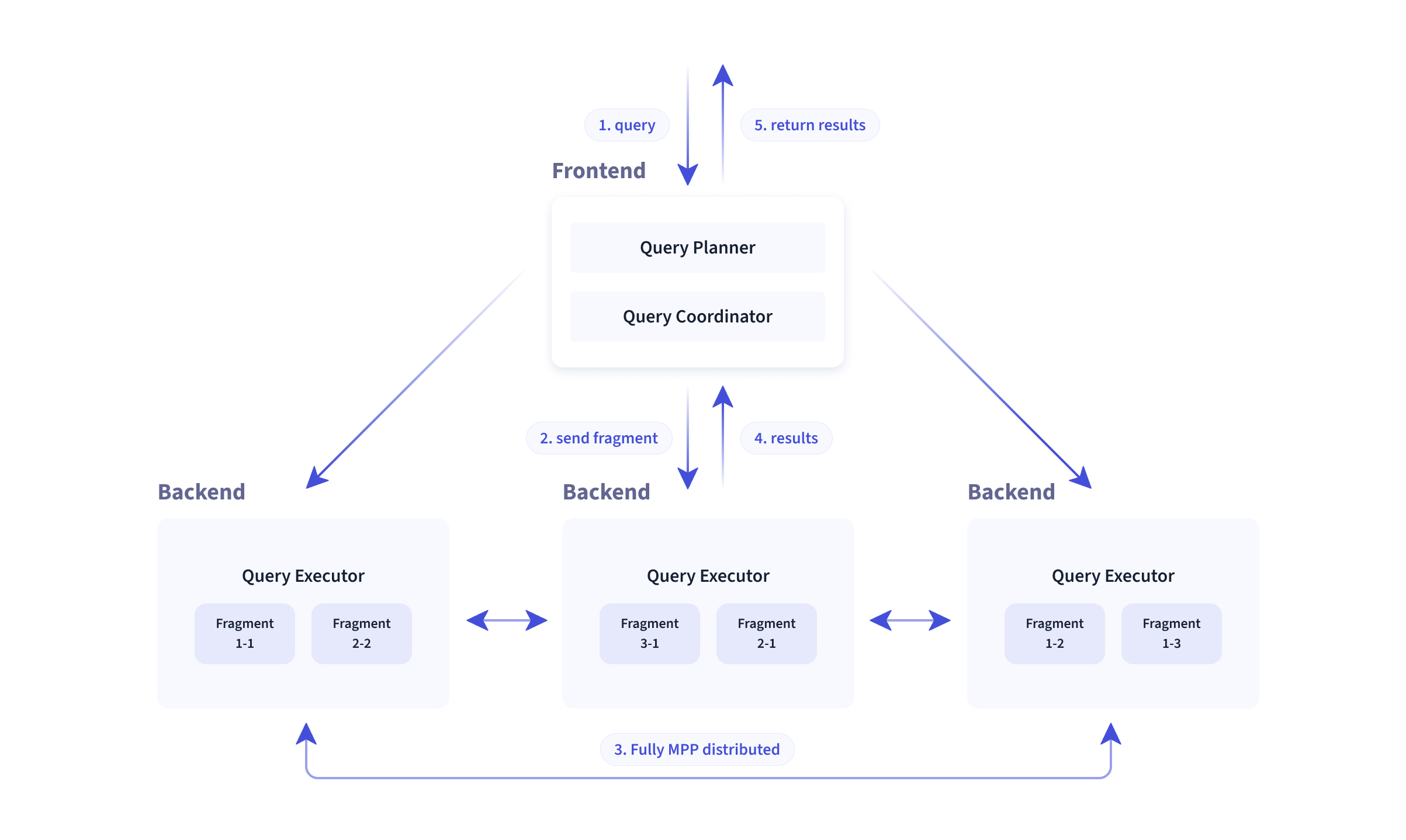
下图展示了 Doris 1FE 多 BE 的体系结构。前端 FE 负责与用户交互、查询优化、元数据管理等,是 Doris 的大脑;后端 BE 负责查询片段的执行和数据存储,部署在集群内每个机器节点上。
在 Doris 中建表需要指定分桶列:
1
2
3
4
5
6
7
8
9
CREATE TABLE sales_order
(
orderid BIGINT,
status TINYINT,
username VARCHAR(32),
amount BIGINT DEFAULT '0'
)
UNIQUE KEY(orderid)
DISTRIBUTED BY HASH(orderid) BUCKETS 10;
分桶 (Bucket) 亦或是分片 (Tablet),是 Doris 中数据移动、复制等操作的最小物理存储单元,换句话说,一个分桶的所有数据存储在同一个 BE 节点上。DISTRIBUTED BY HASH(orderid) BUCKETS 10; 表示该表的每一行将按 orderid 列的哈希值被分到 10 个桶内,而 Doris 进一步将分桶均匀散步到各 BE 节点。每个节点管理的是一张表的不同部分,这是 share-nothing 系统的常见数据排布方式。
MPP 架构中的查询流程
我简单画了一下 MPP 架构的分布式数据库里一条查询的处理流程:
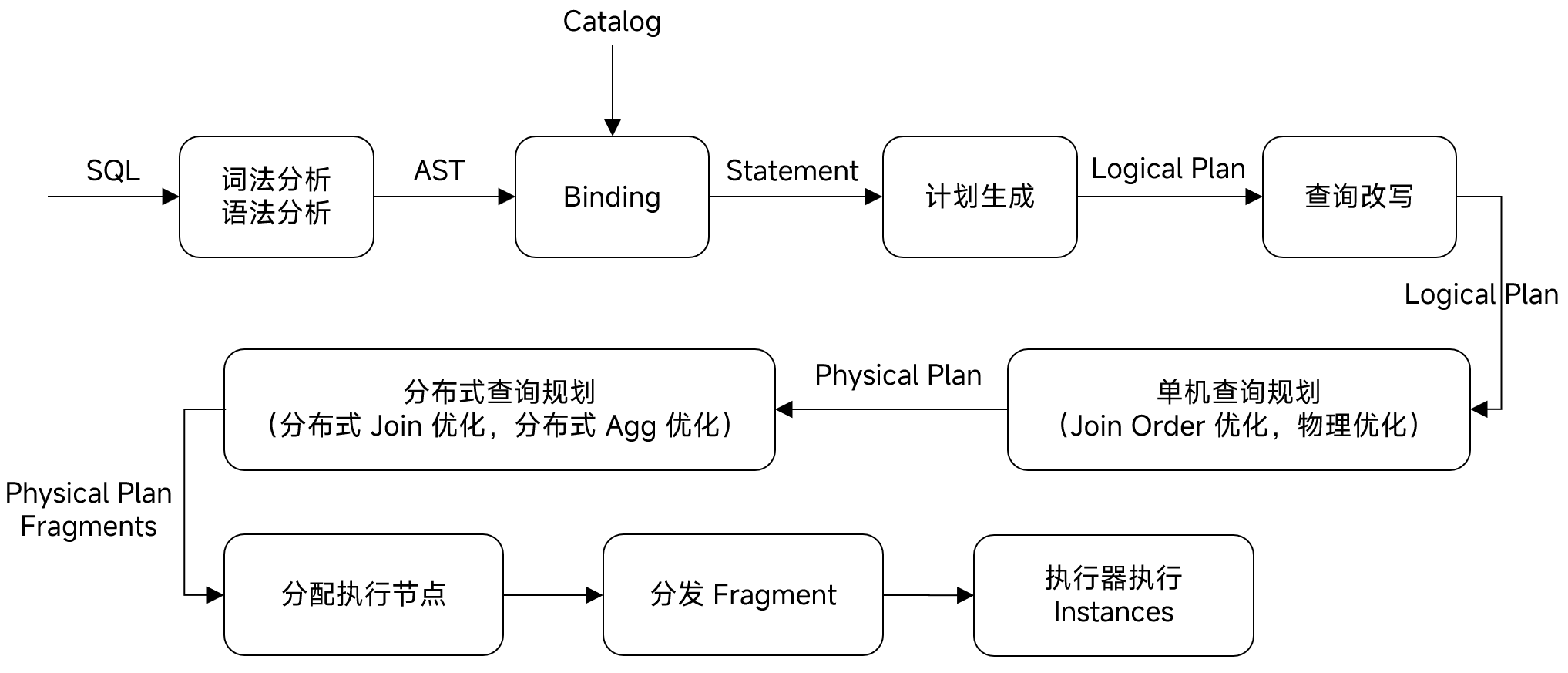
和单机数据库的区别是,MPP 数据库需要在单机查询计划上,进行分布式查询规划,将物理计划切分为一个个片段 (Fragment),最后将这些片段的实例分配分发到执行器所在节点。
在 Doris 中,可使用 EXPLAIN GRAPH sql 等命令查看一个查询的分布式物理计划。下面是部分输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
mysql > EXPLAIN GRAPH SELECT tbl1.k1, sum(tbl1.k2) FROM tbl1 JOIN tbl2 ON tbl1.k1 = tbl2.k1 GROUP BY tbl1.k1 ORDER BY tbl1.k1;
...
| │ |
| ┌─────────────────────────────────┐ |
| │[2: HASH JOIN] │ |
| │[Fragment: 2] │ |
| │join op: INNER JOIN (PARTITIONED)│ |
| └─────────────────────────────────┘ |
| ┌──────────┴──────────┐ |
| ┌─────────────┐ ┌─────────────┐ |
| │[5: EXCHANGE]│ │[6: EXCHANGE]│ |
| │[Fragment: 2]│ │[Fragment: 2]│ |
| └─────────────┘ └─────────────┘ |
| │ │ |
| ┌───────────────────┐ ┌───────────────────┐ |
| │[5: DataStreamSink]│ │[6: DataStreamSink]│ |
| │[Fragment: 0] │ │[Fragment: 1] │ |
| │STREAM DATA SINK │ │STREAM DATA SINK │ |
| │ EXCHANGE ID: 05 │ │ EXCHANGE ID: 06 │ |
| │ HASH_PARTITIONED │ │ HASH_PARTITIONED │ |
| └───────────────────┘ └───────────────────┘ |
| │ │ |
| ┌─────────────────┐ ┌─────────────────┐ |
| │[0: OlapScanNode]│ │[1: OlapScanNode]│ |
| │[Fragment: 0] │ │[Fragment: 1] │ |
| │TABLE: tbl1 │ │TABLE: tbl2 │ |
| └─────────────────┘ └─────────────────┘ |
为了实现并行查询,HASH JOIN 所在的 fragment 2 会有多个实例分别在不同节点执行。扫表所在节点与 HASH JOIN 所在节点间的数据传输由 DataStreamSink 和 Exchange 算子负责。
例如,join 条件为 tbl1.k1 = tbl2.k1,则 fragment 0 中的 DataStreamSink 算子计算元组中 k1 的哈希值,作为接收方的 ID。这样一来,哈希值相同的元组被传输到同一节点继续做 HASH JOIN。
MapReduce 也包含类似过程,我们统一称为 Shuffle 操作。
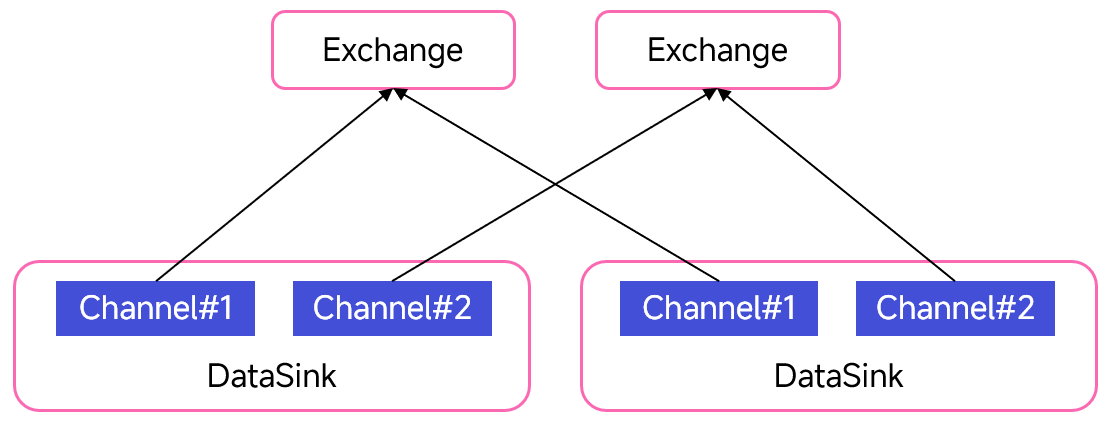
在 Doris 实现中,DataStreamSink 算子内部维护多个 channel,每个 channel 和下游的一个实例一一对应,负责将数据发往对应实例的 Exchange 算子:
分布式查询优化
Doris 把分布式 hash join 划为以下四种方式,它们各有优劣:
1
SELECT * FROM A, B WHERE A.column = B.column;
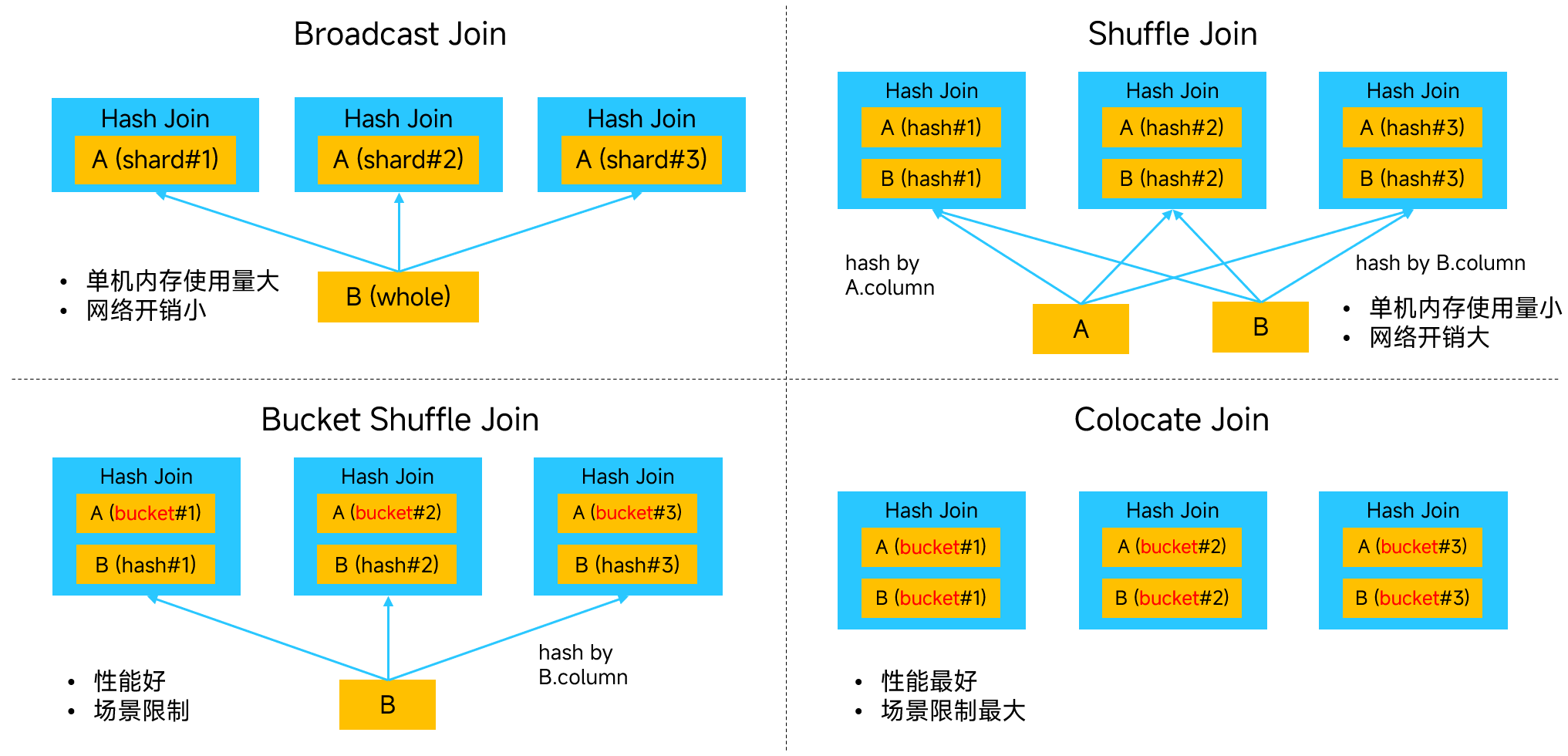
优化时需考虑:
- 先判断两表 join key 是不是都和 distributed key 一样,是就采用开销最小的 colocate join。
- 如果只有一个表一样,就使用性能差一点的 bucket shuffle join。
- 如果都不一样,就要综合各种因素在 broadcast join 和 shuffle join 间做出选择。除了考虑表的大小,还要考虑 join order,这是一个非常复杂的 CBO 问题。
分布式 aggregate 也有优化,例如:
1
SELECT x, sum(y) FROM A GROUP BY x;
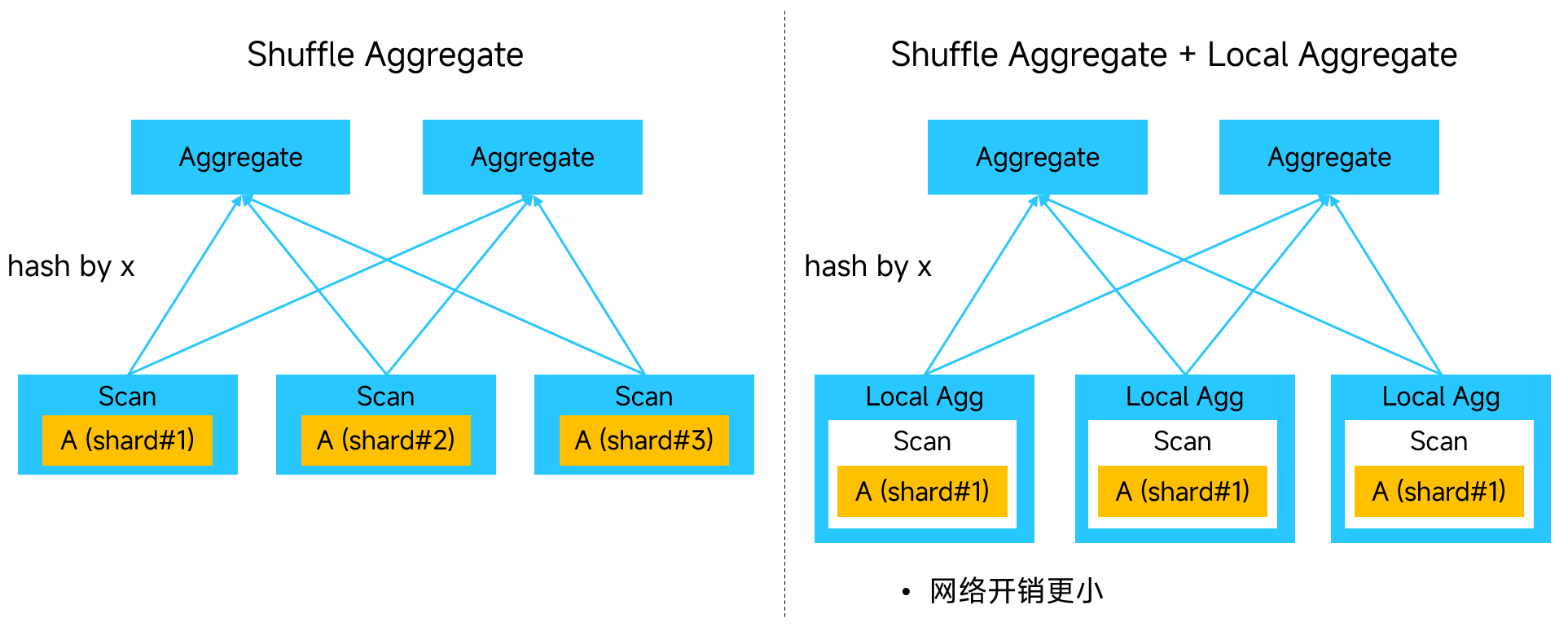
右边相比于左边多出的本地聚合,会提前计算本地元组的 sum(y),以减少网络传输量。
我们来看下面的 SQL Doris 是如何优化的:
1
2
3
4
5
SELECT c_nationkey, sum(o_totalprice)
FROM customer JOIN orders ON
o_custkey = c_custkey
GROUP BY c_nationkey
ORDER BY sum(o_totalprice);
优化结果:
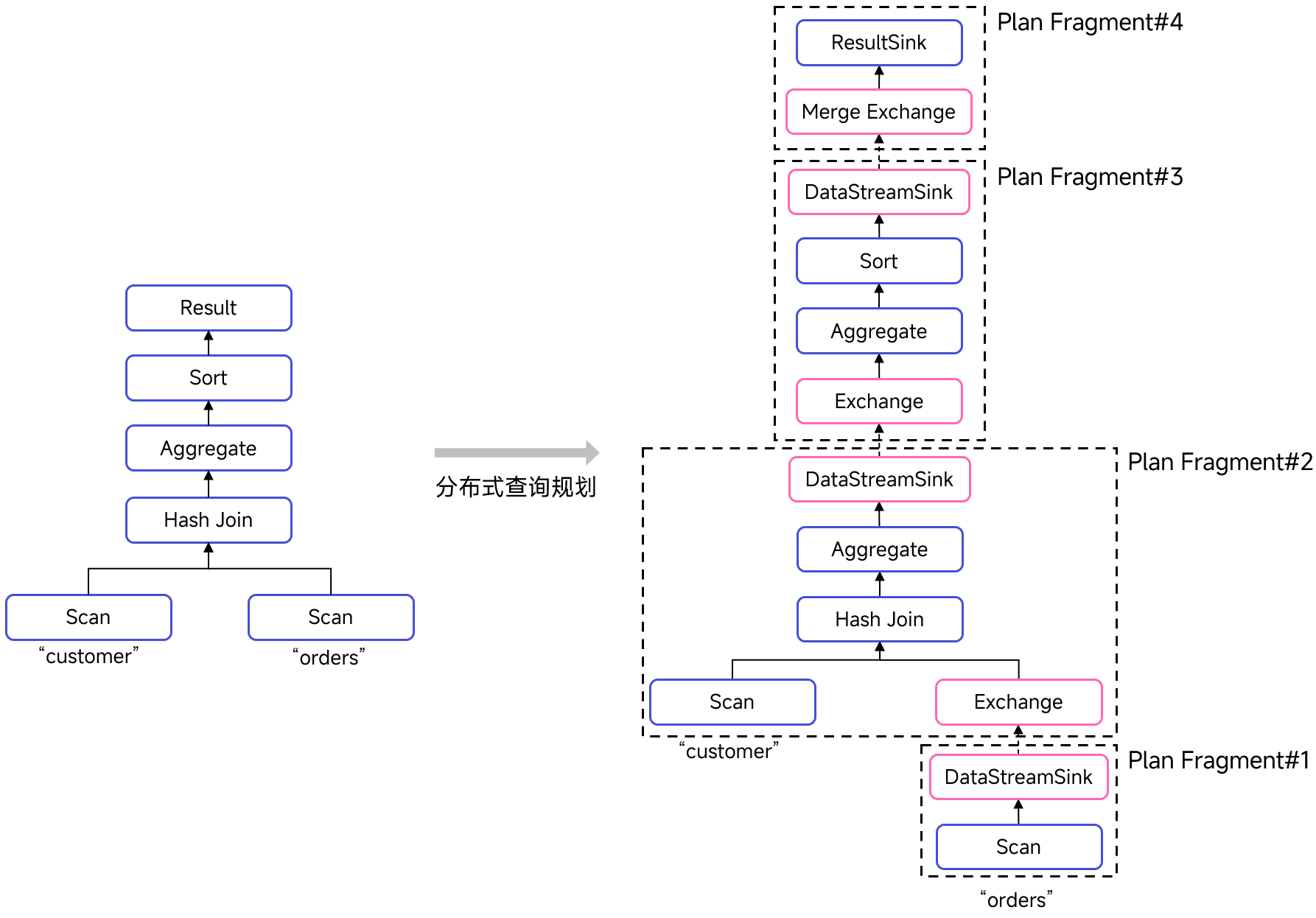
注意两点:
- 为什么 customer 的扫表没有被单独放在一个 fragment?用于 hash 的 c_custkey 也是 customer 的主键,推测 customer 一定是按主键进行了分桶,从而选择了 bucket shuffle join。
- 为什么有两个 aggregate 算子在不同的 fragment?这是前面提到的 local aggregate 优化,在本地元组上计算 sum(o_totalprice),可以减小网络传输量。
查询片段的分配和分发
生成的查询片段被 FE 的 Coordinator 组件分配和分发。分配是指为 fragment 的实例选择执行的 BE 节点,分发是指将 fragment 发往 BE 节点的过程。其中分配分为两步:
- 包含 scan 的 fragment,需要分配到数据所在的 BE 节点上。
- 分配其他不含 scan 的 fragment。实例数量可以通过参数调整。
以上就是关于 Doris 中 MPP 相关内容的介绍。如果对这部分代码感兴趣,可以观看课程视频。
MPP vs. 批处理
我之前看的比较多的是 Ray 分布式计算框架,也调研了其他不少分布式流批处理框架,所以我在刚接触到分布式数据库以及 MPP 时产生了极大的困惑:MPP 中似乎没有动态任务调度器。前面的内容已经说明了这一点:使用 exchange 算子的并行方式需要静态调度,在 Doris 中,查询片段的执行节点也是在分配阶段明确的。
估计出于需要在执行查询前做出调度决策的原因,Doris, ClickHouse 这类分布式数据库也没有针对节点资源使用情况(CPU、内存等)的调度算法,而这种动态调度在分布式批处理框架上十分常见。是什么原因导致了差异呢?
MPP 的缺陷
MPP 存在如下缺陷:
- 集群规模受限:MPP 存在严重的“木桶效应”,整个查询的执行速度会被 straggler 拖慢。当集群规模达到一定程度时,故障会频繁出现使 straggler 成为一个常规问题。
- 并发性能不高:并发性能是指系统同一时间可以执行的有效查询数量,“有效”二字强调每个查询的时延应在合理范围内。在 MPP 中,每个查询都会利用到集群绝大部分节点,不同查询之间 I/O 的相互影响将极大限制系统的并发性能。有资料显示,4 个节点的集群和 400 个节点的集群 MPP 数据库支持的并发查询数是相同的,随着并发数增加,这二者几乎在相同的时间点出现性能骤降。
- 扩容易影响业务连续性:在扩缩容的增删节点操作时,数据重分布就成为一个令人头疼的问题,它的整个操作过程会产生大量的 I/O 请求,引起正常的业务处理速度下降,影响客户的正常查询需求。
我们重点关注和性能相关的前两个缺陷,它们的原因是:
- MPP 为了追求极致的吞吐量和时延,除非迫不得已 (pipeline breaker),都不愿意产生中间数据。这使得实例规模较大,两个同步点 (或者说两个 pipeline breakers) 之间只有一个实例 (pipeline)。这导致动态调度在 MPP 上意义不大,重新调度代价也高,进而无法有效处理 straggler 问题。
- MPP 的静态调度策略不够灵活,无法充分考虑其他查询的影响。包含扫表的实例会绑定到数据所在节点,如果数据分布不合理,将导致并发性能受限。
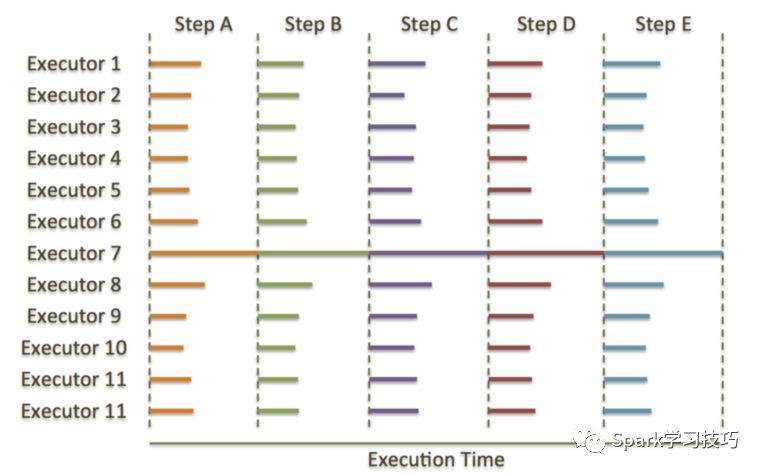
MPP 数据库为了高吞吐量和低时延,牺牲了并发性能和可扩展性。有资料显示,对比当前的 MPP 系统和 Spark 这类系统(相同的硬件环境),Spark 普遍比 MPP 慢 3 到 5 倍。50 个节点的 MPP 集群,性能和 250 的节点的 Spark 集群性能相当,但是 Spark 集群规模可以超过 250 个节点,MPP 做不到。
对比批处理系统
在分布式批处理系统中,任务不是按节点数量划分,而是按输入数据规模划分,单个任务规模较小。而且可根据节点当前负载动态调度,使得 straggler 的影响可以被抹平:
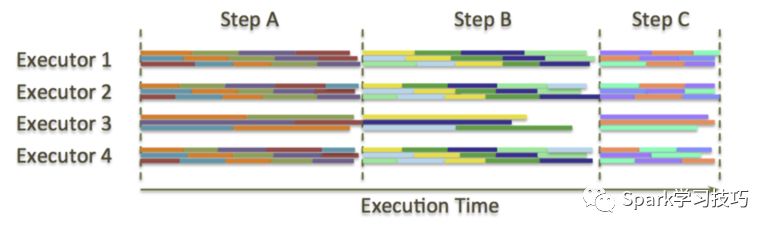
这种做法类似于我们平时编程遇到“木桶效应”的一个解决思路:任务和 CPU 核解绑,使用线程池处理任务,减小任务粒度,并让任务规模尽量相同,先完成任务的线程执行更多的任务。这种思路也和 Morsel-driven parallelism 相似。但所有采取这种任务(更确切的说,是任务的输入数据)和执行器解绑思路的方法,都面临着相同的问题:数据迁移代价。
批处理系统中,数据传输开销一直是影响性能的关键要素。为了减小这种开销,批处理系统的动态调度算法都要考虑 data locality。获取持久化数据方面,由于 HDFS 维护三个副本,可选的较优调度还比较多。中间数据比较麻烦,它只有一份,位置只有在上游任务调度后才能确定。我之前的工作就是在 Ray 上研究这方面的任务调度算法。
批处理系统这种特性使它相比于 MPP 有更高时延和更低吞吐量,事务支持也不够,但同时又获得了更高的并发性能和可扩展性。所以,业界也在结合两种系统的设计思路,探索优势互补的新架构。
存算分离?
存算分离架构的优点是计算集群和存储集群可独立地弹性扩展。显然,传统 MPP 和批处理系统都不适应这样的要求。MPP 数据库存算耦合,而批处理系统不得不通过计算和存储部署在同一物理集群拉近计算与数据的距离,仅在同一集群下构成逻辑存算分离。
国外的 Snowflake, Databricks 实现了存算完全分离,它们是如何做到的?又是如何保障高并发要求和高性能要求的呢?这里我挖一个坑,希望未来能谈一下这些产品的存算分离架构。
参考资料
- Apache Doris 源码阅读与解析系列直播——第四讲 一条SQL的执行过程
- Apache Doris 源码阅读与解析系列直播—— 第八讲 查询优化器详解
- Parallel Execution Framework - TiDB Development Guide
- Viktor Leis, Peter Boncz, Alfons Kemper, and Thomas Neumann. 2014. Morsel-driven parallelism: a NUMA-aware query evaluation framework for the many-core age. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (SIGMOD ‘14).
- mpp架构是什么? - 知乎
- 对比MPP计算框架和批处理计算框架
- 查询分析 - Doris
- 2022 年了,MPP 还是当今数据库主流架构吗?
Comments