LLVM 编译框架的设计决策
这篇文章是为那些完全不了解 LLVM 但对编译器感兴趣的人准备的。我会从 LLVM 的架构开始介绍,然后是 LLVM IR,LLVM 的代码生成器,也会涉及一些 LLVM 后端内容,但不深入到细节。读完这篇文章,希望你能对 LLVM 的设计思路有一个大致的了解。
“LLVM”这个名字曾经是一个首字母缩略词,但现在只是一个品牌名。现在,我们能在 Github 上找到 LLVM 的官方账号,它拥有核心的 LLVM monorepo: llvm-project,以及众多 LLVM 相关的代码仓库。monorepo 表示多个项目的代码都放在一个仓库里,llvm-project 包含了 clang, lldb, mlir 等多个子项目,其中最关键的是 llvm 子项目,它包含了 LLVM IR 和代码生成器的内容。
这篇文章大部分翻译自 The Architecture of Open Source Applications (Volume 1) - LLVM,有兴趣的朋友可以阅读原文。
三阶段设计
传统静态编译器(比如 gcc)最流行的设计是三阶段设计 (three phase design),其主要组件是前端、优化器和后端。

- 前端解析源代码,检查语法错误,并构建特定于语言的抽象语法树(AST)来表示输入代码。AST 可选地被转换为新的表示以进行优化。
- 优化器负责对中间表示进行各种各样的转换,以尝试改善代码的运行时间,例如消除冗余计算。优化器通常或多或少地独立于语言和目标。
- 后端(也称为代码生成器)将中间表示映射到目标指令集。除了要生成正确的代码外,它还负责生成利用目标体系结构特性的高质量代码。编译器后端的常见部分包括指令选择、寄存器分配和指令调度。
一旦当三阶段设计用于多语言多目标编译器的实现时,它的优点就体现出来了。如果在优化器中规定了统一的中间表示 (Intermediate Representation, IR),那么我们可以为一个新前端重用所有后端,为一个新后端重用所有前端。M 种语言和N种目标的编译器,只需要实现 M+N 个组件,而不是 M*N 个组件。LLVM 也采用了这种设计,它所用的中间表示就是 LLVM IR:
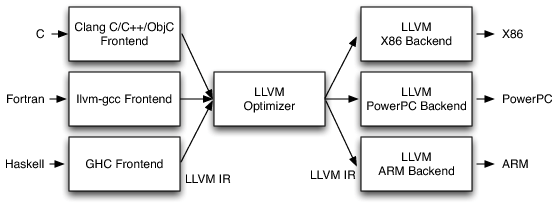
这个模型同样适用于解释器和 JIT 编译器。Java 虚拟机 (JVM) 也是该模型的实现,它使用 Java bytecode 作为前端和优化器之间的接口。
三段式设计还有两个明显的好处:
- 由于支持多语言多目标,能服务更多的程序员。这意味着有一个更大的潜在贡献者社区可以借鉴,这自然会导致对编译器的更多增强和改进。
- 技术上,设计前端和后端的人员可以专注于他们的领域,减少开发难度。
然而实际上,这种设计在过去很长一段时间没有良好的实现。LLVM 之前,三阶段设计只有三个还算成功的实现。第一个是 Java 和 .NET 虚拟机。这些系统提供 JIT 编译器、运行时支持和定义良好的字节码格式。任何可以编译成字节码格式的语言(有几十种)都可以利用优化器和 JIT 以及运行时的工作。但是,它们对于运行时的选择缺乏灵活性,强制使用 JIT 编译器、垃圾回收、特定的对象模型等,所以像 C 语言这种与该模型不太贴合的语言,执行性能欠佳 (LLJVM)。
第二个是将输入源代码转换为 C 代码(或其他语言),并通过现有的 C 编译器生成机器码。这允许重用优化器和代码生成器,提供了良好的灵活性和对运行时的控制。但缺点是很难实现 C 语言所不支持的特性,例如异常处理。
第三个是 GCC。GCC 支持许多前端和后端,并拥有活跃而广泛的贡献者社区。从 GCC 4.4 开始,它有了一个新的优化器表示(称为 “GIMPLE Tuples”),它比以前更接近于与前端的表示分离。然而,GCC 的使用也存在很大的限制。
GCC 被设计为单片应用程序。例如,将 GCC 嵌入到其他应用程序中,将 GCC 用作运行时/ JIT 编译器,或者提取和重用 GCC 的代码片段而不引入编译器大部分组件,这在现实中是不可能的。想要将 GCC 嵌入到自己应用中的人,不得不将 GCC 作为一个单一的应用程序,发出 XML,或者编写插件将外来代码注入 GCC 进程。另外,虽然 GCC 有中间表示 GIMPLE,但它并不是自包含的表示,意味着它的使用需要结合前端或后端的数据结构,缺乏灵活性。
LLVM IR
在了解了历史背景和上下文之后,让我们来深入了解 LLVM 的核心部分:LLVM IR。让我们看下面的 LLVM IR:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
define i32 @add1(i32 %a, i32 %b) {
entry:
%tmp1 = add i32 %a, %b
ret i32 %tmp1
}
define i32 @add2(i32 %a, i32 %b) {
entry:
%tmp1 = icmp eq i32 %a, 0
br i1 %tmp1, label %done, label %recurse
recurse:
%tmp2 = sub i32 %a, 1
%tmp3 = add i32 %b, 1
%tmp4 = call i32 @add2(i32 %tmp2, i32 %tmp3)
ret i32 %tmp4
done:
ret i32 %b
}
对应的 C 代码如下:
1
2
3
4
5
6
7
8
9
unsigned add1(unsigned a, unsigned b) {
return a+b;
}
// Perhaps not the most efficient way to add two numbers.
unsigned add2(unsigned a, unsigned b) {
if (a == 0) return b;
return add2(a-1, b+1);
}
可以看到,LLVM IR 是一个低级的类 RISC 虚拟指令集。LLVM IR 有一些显著的特点:
- 支持简单的运算指令、标签,这使得它看起来某种汇编语言。
- 三地址码 (Three Address Code) 形式,每个三地址码指令,都可以被分解为一个四元组的形式:(运算符,操作数1,操作数2,结果)。
- 静态单赋值 (Static Single Assignment, SSA) 形式,每个变量只能被赋值一次,这使得 LLVM IR 更容易进行优化。
- 有简单类型系统(例如,i32 是一个32位整数)。
- LLVM IR 不使用一组固定的命名寄存器,它使用一组无限的以
%字符命名的临时变量。
除了作为一种语言规范,LLVM IR 还具有三种存在形式:文本格式(以 .ll 结尾的文件)、字节码(以 .bc 结尾的文件)、内存内的数据结构。LLVM 提供 llvm-as 和 llvm-dis 工具来在文本格式和字节码之间进行转换。
LLVM IR 是良好定义的,并且是到优化器的唯一接口。这其实是 LLVM 取得成功的重要原因。即使是广泛成功且架构相对良好的 GCC 编译器也不具有此属性:它 GIMPLE 中间表示不是自包含的表示。举个例子,当 GCC 代码生成器发出 DWARF 调试信息时,它会返回并遍历源码级的“树”形式。
这意味着前端作者需要知道并生成 GCC 的树数据结构以及 GIMPLE 来编写 GCC 前端。GCC 后端也有类似的问题。GCC 没有办法转储出“表示代码的一切”,也没有办法以文本形式读写 GIMPLE(以及构成代码表示的相关数据结构)。
LLVM IR 优化
大多数优化都遵循简单的三步骤:
- 寻找一种模式来转换。
- 验证转换对于匹配的实例是否安全/正确。
- 执行转换,更新代码。
最简单的一个优化是算术恒等式的模式匹配 (pattern match):对于任何整数 X, X-X 是 0, X-0 是 X,(X*2)-X 是 X。它们在 LLVM IR 如下所示:
1
2
3
4
5
6
7
8
⋮ ⋮ ⋮
%example1 = sub i32 %a, %a
⋮ ⋮ ⋮
%example2 = sub i32 %b, 0
⋮ ⋮ ⋮
%tmp = mul i32 %c, 2
%example3 = sub i32 %tmp, %c
⋮ ⋮ ⋮
对于这些窥孔 (peephole) 转换(即关注很小一组指令的优化),LLVM 提供了一个指令简化接口,被其他高级转换所使用。它定义在 SimplifySubInst 函数里,看起来像这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// X - 0 -> X
if (match(Op1, m_Zero()))
return Op0;
// X - X -> 0
if (Op0 == Op1)
return Constant::getNullValue(Op0->getType());
// (X*2) - X -> X
if (match(Op0, m_Mul(m_Specific(Op1), m_ConstantInt<2>())))
return Op1;
…
return 0; // Nothing matched, return null to indicate no transformation.
在此代码中,Op 0 和 Op 1 绑定到整数减法指令的左右操作数。LLVM是用C++实现的,C++的模式匹配功能并不出名(与 Objective Caml 等函数式语言相比),但它确实提供了一个非常通用的模板系统,允许我们实现类似的东西。match 函数和 m_ 函数允许我们对 LLVM IR 代码执行声明性模式匹配操作。例如,只有乘法的左操作数与 Op 1 相同时,m_Specific 谓词才匹配。
总之,如果模式匹配成功,函数返回替换,否则返回空指针。这个函数的调用者是一个 Pass,看起来像这样:
1
2
3
for (BasicBlock::iterator I = BB->begin(), E = BB->end(); I != E; ++I)
if (Value *V = SimplifyInstruction(I))
I->replaceAllUsesWith(V);
这段代码简单地遍历块中的每条指令,检查它们是否简化。如果可以,它使用 replaceAllUsesWith 方法更新代码。
为了便于管理,转换会在一个 Pass 中实现,而一个 Pass 一般代表某类优化。例如, GVNLegacyPass 是一个包含 GVN 优化的 Pass,它执行与公共子表达式消除 (CSE) 类似的冗余代码消除的优化转换。我们可以在 llvm/lib/Transforms 目录下找到这些预先定义的 Pass 和转换的实现,LLVM 也支持我们定义自己的 Pass。
要使用 Pass,一般需要创建一个 PassManager,然后我们将要执行的 Pass 对象添加到 PassManager 中。当执行 PassManager 的 run 方法时,它会去依次调用 Pass 对象的处理函数(比如 runOnFunction)。在这个处理函数里,Pass 使用模式匹配的方式对代码进行优化转换。
LLVM 代码生成器
LLVM 代码生成器 (code generator) 负责将 LLVM IR 转换成目标特定的机器代码。尽管不同目标有着不同的指令格式、寄存器堆等,但在代码生成时都需要解决非常相似的问题,这是 LLVM 代码生成器重用代码的基础。
与优化器中的方式类似,LLVM 的代码生成器将代码生成问题分为多个独立的 Pass,包括指令选择、寄存器分配、指令调度、汇编发射等,并提供许多内置的默认 Pass。后端编写者可以在默认 Pass 中进行选择,并根据需要实现完全自定义的目标特定 Pass。
例如,x86 后端使用减少寄存器压力(减少对寄存器的需求,减少寄存器释放和分配次数)的指令调度器,因为它只有很少的寄存器,而 PowerPC 后端使用优化延迟(最大程度地减少指令的执行延迟)的调度器,因为它有很多寄存器。x86 后端使用自定义 Pass 处理 x87 浮点堆栈,而 ARM 后端使用自定义 Pass 在函数内部放置常量池岛。这种灵活性使得目标作者能够在不必从头开始编写整个代码生成器的情况下生成优秀的代码。
目标描述文件
LLVM 代码生成器的设计方法允许目标作者选择对他们的体系结构有意义的内容,并允许在不同目标之间重用大量代码。这带来了另一个挑战:每个共享组件需要能够以通用方式推理目标特定属性。例如,共享的寄存器分配器需要知道每个目标的寄存器文件以及存在于指令与它们的寄存器操作数之间的约束。LLVM 对此的解决方案是让每个目标提供一个由 tblgen 工具处理的声明性的的目标描述。x86 目标的描述文件包括(简化的):
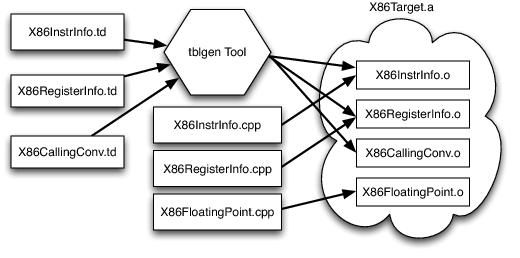
x86 后端定义了一个寄存器类,它包含所有名为“GR32”的 32 位寄存器(在文件中,目标特定的定义都是大写的),如下所示:
1
2
3
def GR32 : RegisterClass<[i32], 32,
[EAX, ECX, EDX, ESI, EDI, EBX, EBP, ESP,
R8D, R9D, R10D, R11D, R14D, R15D, R12D, R13D]> { … }
这个定义表示该类寄存器可以容纳 32 位整数值(i32),最好是 32 位对齐的,具有指定的 16 个寄存器(在其他 .td 文件中定义),并且还有一些其他信息来指定首选分配顺序和其他内容。根据这个定义,特定的指令可以引用这 16 个寄存器作为操作数。例如,“对 32 位寄存器求补” 指令的定义如下:
1
2
3
4
5
let Constraints = "$src = $dst" in
def NOT32r : I<0xF7, MRM2r,
(outs GR32:$dst), (ins GR32:$src),
"not{l}\t$dst",
[(set GR32:$dst, (not GR32:$src))]>;
第一行的 let 约束告诉寄存器分配器输入和输出寄存器必须分配给同一个物理寄存器。
该定义表明 NOT32r 是一条指令(它使用 I tblgen 类),指定编码信息(0xF7, MRM2r),指定它定义“输出”32位寄存器 $dst 并且具有名为“输入”的32位寄存器 $src(上面定义的 GR32 寄存器类定义了哪些寄存器对于操作数有效),指定指令的汇编格式(使用 {} 来处理 AT&T 和 Intel 不同的格式),并在最后一行提供指定指令的效果和它应该匹配的模式。
这个定义是指令的一个非常密集的描述。它可以用于从 LLVM IR 模式匹配生成该指令,可以用于寄存器分配器如何给该指令分配物理寄存器,可以指示如何打印该指令,等等。由于它是对指令的集中描述,所以并不容易出现不一致,例如,汇编器和反汇编器都依赖于该描述,它们几乎不可能在汇编语法或二进制编码中彼此不一致。
尽管这个声明式的描述包含了许多信息,仍然还有大量信息需要目标作者编写 C++ 代码来提供,例如任何特定于目标的 Pass(比如处理 x87 浮点堆栈)。
LLVM 的模块化设计
前面我们大致讲了 LLVM 的每个阶段,可以总结出 LLVM 的一个重要设计准则:代码可重用性,例如 LLVM IR 优化 Pass 以及后端各种目标无关算法。这一部分我们进一步介绍 LLVM 在面向代码开发者还做了哪些方面的努力来提供便捷性和灵活性。
LLVM 是库的集合
LLVM 被设计为一组库,而不是像 GCC 那样单一的命令行编译器,或者像 JVM 或 .NET 虚拟机那样的不透明虚拟机。这是 LLVM 最重要的优势之一,也是我们最容易忽视的优势。
让我们以优化器的设计为例:它读取 LLVM IR,稍微处理一下,然后发出 LLVM IR,希望它执行得更快。前面提到,LLVM (和许多其他编译器一样)将优化器组织为不同优化 Pass 的组合。根据优化级别 (比如 -O1 和 -O3),不同的 Pass 被执行。
每个 LLVM 传递都被写为一个 C++ 类,它(间接)派生自 Pass 类。下面是一个例子:
1
2
3
4
5
6
7
8
9
10
11
12
namespace {
class Hello : public FunctionPass {
public:
// Print out the names of functions in the LLVM IR being optimized.
virtual bool runOnFunction(Function &F) {
cerr << "Hello: " << F.getName() << "\n";
return false;
}
};
}
FunctionPass *createHelloPass() { return new Hello(); }
LLVM 优化器提供了几十种不同的 Pass,每一种都以类似的风格编写。这些 Pass 被编译成一个或多个文件,然后构建成一系列静态库。
当我们需要针对特定领域代码的优化编译开发工具时,一旦选择了优化集合,这些选定的 Pass 就被构建到可执行文件或动态库中。由于对LLVM 优化 Pass 的唯一引用是每个文件中定义的函数,并且由于优化器位于静态库中,因此只有实际使用的优化 Pass 被链接到最终应用程序中,而不是整个 LLVM 优化器。
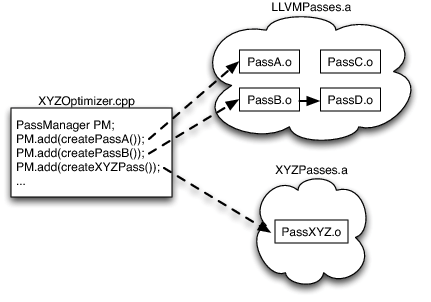
在图中的例子中,由于有一个对 PassA 和 PassB 的引用,它们将被链接。由于 PassB 使用 PassD 进行一些分析,因此 PassD 被链接。但是,由于没有使用 PassC(以及其他数十种优化),因此其代码不会链接到我们的应用程序中。
上述的链接模式同样适用于哪些使用 LLVM 代码生成器 Pass 编写应用程序的场景。在 libLLVMCodeGen.a 中,只有被使用到的 Pass 对象文件会被链接到最终的应用程序中。
这种简单的设计允许 LLVM 提供大量的功能,但又不影响那些只想做简单事情的库使用者。相比之下,传统的编译器优化器被构建为紧密互连的大量代码,这更难以子集划分、推理和快速上手。
决定阶段执行时机
前端、优化器、后端模块化的设计还让 LLVM 为用户提供了一些有趣的功能。
如前所述,由于 LLVM IR 是自包含的,并且它的序列化是一个无损过程,因此我们可以执行部分编译,将进度保存到磁盘,然后在将来的某个时候继续工作。这个特性提供了许多有趣的功能,包括对链接时和安装时优化的支持,这两个功能都将代码生成从“编译时”延迟。
链接时间优化 (Link-Time Optimization, LTO) 解决了编译器传统上仅看到一个翻译单元(一个源文件及其包含的所有头文件),因此不能跨文件边界进行优化(如内联)的问题。像 Clang 这样的 LLVM 编译器通过 -flto 或 -O4 选项支持这一点。该选项指示编译器将 LLVM bitcode 发送到 .o 文件,而不是写出原生对象文件,并将代码生成延迟到链接时间:

具体细节取决于你使用的操作系统,但重要的是链接器检测到文件中有 LLVM bitcode,而不是原生对象文件。这时,它将所有 itcode 文件读入内存,将它们链接在一起,然后在链接产物上运行 LLVM 优化器。由于优化器现在可以看到更大部分的代码,它可以内联、传播常量、执行更积极的死代码消除,以及更多的跨文件边界优化。
虽然许多现代编译器支持 LTO,但它们中的大多数(例如,GCC、Open64、Intel 编译器等)这是通过代价高且缓慢的串行化过程来实现的。在 LLVM 中,LTO 从系统的设计中自然而然的得到,并且可以跨不同的编程语言工作(与许多其他编译器不同),因为 LLVM IR 是真正的语言中立的。
安装时优化是将代码生成延迟到链接之后,一直到安装时间,如下图所示。例如,在 x86 系列中,存在各种各样的芯片和特性。通过延迟指令选择、调度和代码生成的其他方面,你可以为应用程序最终运行的特定硬件生成最佳代码。

Comments