为什么需要动态链接?
首先我们来回答一下标题的问题,为什么需要动态链接?动态链接的目的如下:
- 节约内存和磁盘空间:使用静态链接,同一个库被一定数量程序链接,在磁盘上和内存中都相等于多了相同数量的库的副本。
- 方便程序开发和发布:假如静态库由第三方提供,如果它更新了,整个程序都要重新编译。
为了解决以上问题,我们让程序在构建时不链接某些目标文件,而是等到程序运行时再链接,这就是动态链接。动态链接还有一些其他用途:
- 制作插件:提前定义好程序接口,其他开发者根据接口规范开发动态链接库。
- 增强系统兼容性:一个程序在不同的平台可以链接到不同的系统库。通过使用相同的接口定义,可以消除程序对系统的依赖。
动态链接的缺点也非常明显。动态链接将链接操作推迟到运行时,对程序性能产生了影响。程序在发布时,还需要处理各种库依赖问题。
装载时重定位
如果一个动态链接库(Linux 下叫共享库)只能装载到固定地址,那么它想要被多个进程使用是非常困难的,因为不可能每个进程都给它预留指定的空间。因此,我们需要共享对象能在任意地址加载。或者说,共享对象在编译时不能假设自己在进程虚拟地址空间中的位置。
一个思路是将重定位从链接时推迟到装载时。一旦模块装载地址确定,即目标地址确定,系统就对程序中所有的绝对地址引用进行重定位。我们将静态链接中的重定位称为链接时重定位 (link time relocation),这里的方法称为装载时重定位 (load time relocation)。
但是通过修改指令的装载时重定位并不适合解决上述问题。动态链接库被装载后,指令部分是需要在多个程序之间共享的,否则动态链接节省内存的优势就荡然无存了。如果装载重定位需要修改指令,就没有办法做到同一份指令被多个程序共享。为了解决该问题,需要在装载时重定位中使用 PIC 技术。
在 64 位架构上,GCC 已经不再支持无 PIC 的装载时重定位,想要编译动态链接库,必须使用 PIC 技术:
Shared libs need PIC on x86-64, or more accurately, relocatable code has to be PIC. This is because a 32-bit immediate address operand used in the code might need more than 32 bits after relocation. If this happens, there is nowhere to write the new value. source
地址无关代码和全局偏移表
首先,我们解释地址无关代码 (Position-independent Code, PIC) 的实现原理。PIC 在 DYN 类型的 ELF 文件中存在,即 PIC 在 PIE、共享库、解释器(动态链接器)三类 ELF 文件中存在。我们利用一个简单的共享库解释 PIC 的实现原理。不使用 PIE 的原因是,可执行文件会引入许多和我们主题无关的代码。
通过以下命令生成一个简单的共享库:
1
2
gcc -fno-plt -fPIC -c pic.c
gcc -shared -o libpic.so pic.o
-fPIC 选项生成地址无关代码,是共享库能够节省内存的基础。关于 -fno-plt 会在后面解释。
我们将一个共享库、一个可执行文件都称为一个模块。
我们的测试代码如下。下面分别分析 PIC 中 a, b, bar, ext 几个符号的处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// pic.c
static int a;
extern int b;
int c;
extern void ext();
static void dog()
{
a = 2;
}
void bar()
{
a = 1;
b = 2;
c = 3;
}
void foo()
{
dog();
bar();
ext();
}
我们可以通过以下命令查看动态符号表 (.dynsym):
1
2
3
4
5
6
7
8
9
10
11
12
13
$ readelf -sD libpic.so
Symbol table for image contains 10 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND ext
2: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND b
3: 0000000000000000 0 NOTYPE WEAK DEFAULT UND __cxa_finalize
4: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_registerTMC[...]
5: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_deregisterT[...]
6: 0000000000000000 0 NOTYPE WEAK DEFAULT UND __gmon_start__
7: 0000000000004024 4 OBJECT GLOBAL DEFAULT 20 c
8: 000000000000113d 43 FUNC GLOBAL DEFAULT 10 foo
9: 000000000000110e 47 FUNC GLOBAL DEFAULT 10 bar
静态符号表 (.symtab) 包含了动态符号表。而动态符号表只包含和动态链接有关的符号。可以看到,函数 bar 和 foo 是有定义的,被称为导出函数,而 ext 是没有定义的,被称为导入函数。除了没有定义的 b 和 ext 需要重定位以外,由于全局符号介入 (Global Symbol Interpose) 机制的存在,像 c 和 bar 这样有定义的符号都需要重定位。
变量 a 和函数 dog 都是静态的,不会被导出,因此不会出现在动态符号表中。
静态变量与静态函数
在函数 bar() 中,a = 1; 语句的机器码如下:
1
2
3
4
5
$ objdump -d libpic.so
# ...
1116: c7 05 08 2f 00 00 01 movl $0x1,0x2f08(%rip) # 4028 <a>
111d: 00 00 00
1120: # ...
1
2
3
4
5
6
7
8
9
10
11
12
13
# 查看符号表
$ objdump -t libpic.so
# ...
0000000000004028 l O .bss 0000000000000004 a
# ...
# 查看段表
$ objdump -h libpic.so
Sections:
Idx Name Size VMA LMA File off Algn
# ...
19 .bss 00000008 0000000000004020 0000000000004020 00003020 2**2
ALLOC
# ...
对变量 a 采用了 rip + offset 的寻址方式,rip 保存下一条有效指令的地址,在这里是 0x1120 + 装载地址,而 0x1120 + 0x2f08 就是 0x4028。查看符号表可以发现,变量 a 在 .bss 段内,映像内地址就是 0x4028。
在函数 foo() 中,dog(); 语句的机器码如下:
1
2
3
4
5
6
$ objdump -d libpic.so
# ...
114a: e8 aa ff ff ff call 10f9 <dog>
# ...
$ objdump -t libpic.so
00000000000010f9 l F .text 0000000000000015 dog
发现 dog 函数就在 .text Section 内,直接调用即可。由于 call 是基于偏移调用函数的,装载时也不需要修改命令。
可见,静态变量和静态函数不存在跨模块引用或跨模块调用。对于这种符号,直接采用偏移量定位,装载时不需要重定位处理。无论映像被装载到哪个地址,指令都能用下条指令地址 + offset 的方式正确访问到变量。
全局变量声明和定义
1
2
3
4
5
6
7
$ objdump -d libpic.so
# ...
1120: 48 8b 05 a1 2e 00 00 mov 0x2ea1(%rip),%rax # 3fc8 <b>
1127: c7 00 02 00 00 00 movl $0x2,(%rax)
112d: 48 8b 05 ac 2e 00 00 mov 0x2eac(%rip),%rax # 3fe0 <c-0x44>
1134: c7 00 03 00 00 00 movl $0x3,(%rax)
# ...
赋值变量 b/c 时,首先采用 rip + offset 的方式访问到变量 b/c 的地址,然后将地址写入到 %rax 寄存器中,最后通过 %rax 寄存器间接寻址访问到变量 b/c。所以为什么要采用这种方式呢?
变量 b 在模块内是未定义的,变量 c 由于全局符号介入,它们的虚拟地址都只有等到装载时才能确定。ELF 的做法是建立一个 .got Section,里面是一个指向变量实际地址的指针,该 Section 被称为全局偏移表 (Global Offset Table, GOT)。由于 GOT 相对指令的偏移是固定的,所以获取变量 b/c 时,先获取对应的 GOT 表项,即 b/c 的实际虚拟地址,再通过寄存器间接寻址访问 b/c。
我们可以在需要重定位的符号中找到 b/c:
1
2
3
4
5
6
$ objdump -R libpic.so
DYNAMIC RELOCATION RECORDS
OFFSET TYPE VALUE
# ...
0000000000003fc8 R_X86_64_GLOB_DAT b
0000000000003fe0 R_X86_64_GLOB_DAT c
1
2
3
4
5
6
$ objdump -h libpic.so
Sections:
Idx Name Size VMA LMA File off Algn
# ...
16 .got 00000040 0000000000003fc0 0000000000003fc0 00002fc0 2**3
CONTENTS, ALLOC, LOAD, DATA
每个表项都是一个指针,占 8 个字节,那么这里的 b 就是 GOT 的第 2 个表项,c 是第 5 个表项。动态链接器在装载模块时,会查找每个这样的变量的地址,然后填充 GOT 中的各个项。
这里的 GOT 就是 PIC 能节省内存的关键。共享库被装入内存后,指令部分是在多个进程间共享的,不能被修改。 同一个共享库在不同进程地址空间中的位置不同,变量或函数的实际地址也可能不同(例如进程 1 的 b 在模块 M 中定义,而进程 2 的 b 在模块 N 中定义)。倘若要在指令中嵌入变量 b 的偏移或地址,则必须通过修改指令进行重定位,这违背了一份代码的原则。使用 GOT 后,重定位不需要修改指令,而是通过修改 GOT 表项完成的。GOT 可看做一种数据段,而共享库的数据段在不同进程都是有副本的,所以修改 GOT 是完全合法的。
那么为什么模块内有定义的符号也要重定位(改 GOT)呢?
全局符号介入机制要求,所有的全局符号都必须在装载时被重定位。 我们这里定义了 c,并不意味着最终 c = 3; 语句会使用本模块的 c。全局符号介入可以简单概述为:当多个模块内存在同名符号(不包括静态符号)时,最终会使用唯一的一份数据,使用哪一个模块的定义取决于模块的装载顺序。先装载的模块的符号被使用,后面出现的同名符号被忽略。 模块装载顺序一般是广度优先策略,主程序视为第一个装载的模块。因此,全局变量的实际地址也只有装载时才能确定,也需要重定位。
例如,对于下面的模块:
1
2
3
4
5
gcc -fPIC -shared a1.c -o a1.so
gcc -fPIC -shared a2.c -o a2.so
gcc -fPIC -shared b1.c a1.so -o b1.so
gcc -fPIC -shared b2.c a2.so -o b2.so
gcc main.c b1.so b2.so -fPIC -o main
装载顺序为:
1
main -> b1 -> b2 -> a1 -> a2
我们可以通过查看 VMA 布局来获取装载顺序:
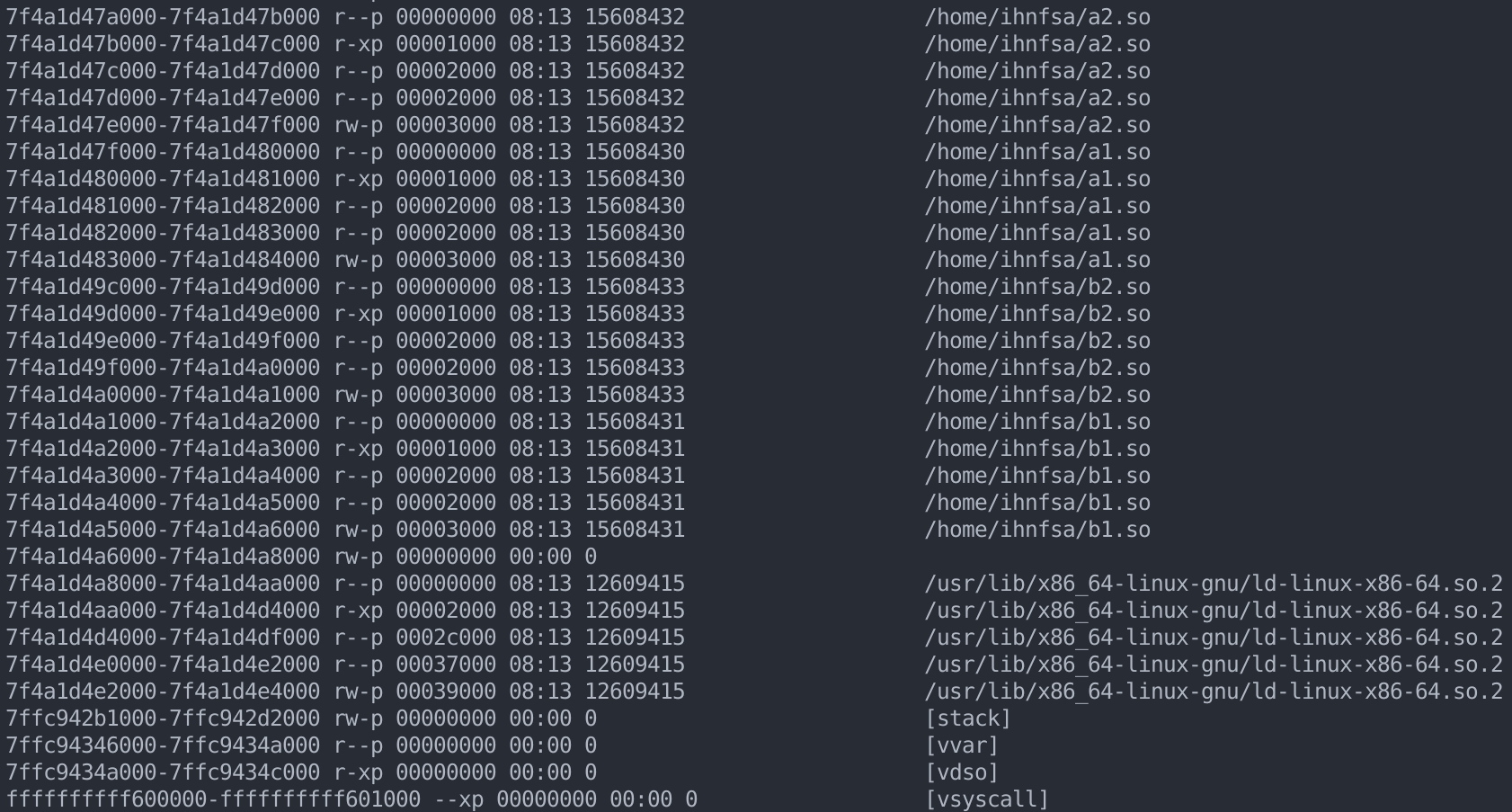
函数声明和定义
查看函数调用的反汇编代码:
1
2
3
4
5
6
$ objdump -d libpic.so
# ...
114f: b8 00 00 00 00 mov $0x0,%eax
1154: ff 15 96 2e 00 00 call *0x2e96(%rip) # 3ff0 <bar+0x2ee2>
115a: b8 00 00 00 00 mov $0x0,%eax
115f: ff 15 5b 2e 00 00 call *0x2e5b(%rip) # 3fc0 <ext>
可以看到,这里使用的地址 3ff0 和 3fc0 都是在 GOT 内:
1
2
3
$ objdump -R libpic.so
0000000000003fc0 R_X86_64_GLOB_DAT ext
0000000000003ff0 R_X86_64_GLOB_DAT bar
这符合我们前面的分析,函数 bar() 和函数 ext() 都是全局符号,都需要重定位,而且都是通过 GOT 表项来重定位的。唯一需要我们特别注意的是,这里的 call 指令的采用了一种取值 * 的方式获取函数地址。
延迟绑定与 Procedure Linkage Table (PLT)
动态链接比静态链接慢的原因有两个:
- 对全局非静态变量的访问需要通过 GOT 表项间接访问。
- 链接工作在运行时完成。
延迟绑定是 ELF 针对问题 2 的一种优化技术,它的思想是:函数只有在第一次调用时才进行绑定(符号查找、重定位等),如果没有用到则不进行绑定。 这样可以加快程序的启动速度。
现在,我们去掉 -fno-plt,打开默认的 PLT。可以发现,变化集中于对 bar() 和 ext() 函数的调用。所以,这里也强调 PLT 仅针对函数调用。
1
2
3
4
5
6
$ objdump -d libpic.so
# ...
118f: b8 00 00 00 00 mov $0x0,%eax
1194: e8 d7 fe ff ff call 1070 <bar@plt>
1199: b8 00 00 00 00 mov $0x0,%eax
119e: e8 bd fe ff ff call 1060 <ext@plt>
这里调用了两个在 .plt.sec 段的函数 bar@plt 和 ext@plt,它们的反汇编:
1
2
3
4
5
6
7
8
9
10
11
12
13
$ objdump -d libpic.so
# ...
Disassembly of section .plt.sec:
0000000000001060 <ext@plt>:
1060: f3 0f 1e fa endbr64
1064: f2 ff 25 ad 2f 00 00 bnd jmp *0x2fad(%rip) # 4018 <ext>
106b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
0000000000001070 <bar@plt>:
1070: f3 0f 1e fa endbr64
1074: f2 ff 25 a5 2f 00 00 bnd jmp *0x2fa5(%rip) # 4020 <bar+0x2ed2>
107b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
我们先看 4018 和 4020,在哪个段:
1
2
3
4
5
6
7
8
9
$ objdump -R libpic.so
# ...
0000000000004018 R_X86_64_JUMP_SLOT ext
0000000000004020 R_X86_64_JUMP_SLOT bar
$ objdump -h libpic.so
# ...
19 .got.plt 00000028 0000000000004000 0000000000004000 00003000 2**3
CONTENTS, ALLOC, LOAD, DATA
可以看到,在开启 PLT 后,ext 和 bar 的地址不在 .got 段,而是在 .got.plt 段。而全局变量仍然在 .got 段。
现在我们来看,got.plt 段都存放了什么内容:
1
2
3
4
5
$ objdump -s libpic.so
Contents of section .got.plt:
4000 503e0000 00000000 00000000 00000000 P>..............
4010 00000000 00000000 30100000 00000000 ........0.......
4020 40100000 00000000
以 8 字节为一个表项:
1
2
3
4
5
4000: 3e50 # .dynamic section
4008: 0
4010: 0
4018: 1030 # ext
4020: 1040 # bar
所以,实际上会调用 1030 和 1040 处的函数,这两个函数位于 .plt 段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
$ objdump -d libpic.so
# ...
Disassembly of section .plt:
0000000000001020 <.plt>:
1020: ff 35 e2 2f 00 00 push 0x2fe2(%rip) # 4008 <_GLOBAL_OFFSET_TABLE_+0x8>
1026: f2 ff 25 e3 2f 00 00 bnd jmp *0x2fe3(%rip) # 4010 <_GLOBAL_OFFSET_TABLE_+0x10>
102d: 0f 1f 00 nopl (%rax)
1030: f3 0f 1e fa endbr64
1034: 68 00 00 00 00 push $0x0
1039: f2 e9 e1 ff ff ff bnd jmp 1020 <_init+0x20>
103f: 90 nop
1040: f3 0f 1e fa endbr64
1044: 68 01 00 00 00 push $0x1
1049: f2 e9 d1 ff ff ff bnd jmp 1020 <_init+0x20>
104f: 90 nop
可以看到,1030 和 1040 处的函数分别 push 了一个 0 和 1,然后跳转到了 1020 处。1020 处又 push got.plt 的第二个表项,然后跳转到了第三个表项 4010 处。
查阅资料,发现 .got.plt 前几个表项的含义如下:
1
2
3
4
5
4000: 3e50 # .dynamic section
4008: 0 # Module ID
4010: 0 # _dl_runtime_resolve
4018: 1030 # ext
4020: 1040 # bar
所以这里实际上,是调用了 _dl_runtime_resolve 进行运行时的绑定工作。.got.plt 也是一种数据段,当 _dl_runtime_resolve 解析完成后,会将解析结果写入 .got.plt 的相应表项,下一次调用时,就直接跳转到实际函数地址。
注意,这里调用 _dl_runtime_resolve 仅使用了栈来传递参数,而非 rdi, rsi, rdx, … Linux 惯用的调用约定。别忘了当前正处于函数调用过程中,这些寄存器存放了函数调用的参数。
_dl_runtime_resolve 的声明可以看作 _dl_runtime_resolve(link_map, reloc_index),这里的 link_map 就是第二个 .got.plt 表项,reloc_index 可以看作 .got.plt 第几个需要修改的表项。
重定位表
我们可以通过 readelf -r 查看共享库的重定位信息(objdump -r 无法查看)。共享库只有两个重定位表/段,一个是 rela.dyn,一个是 rela.plt。在开启 PLT 的情况下,rela.dyn 用于重定位 .got 中的变量和数据段中的变量。rela.plt 用于重定位 .got.plt 中的函数。 如果没有开启 PLT,rela.dyn 将包含 GOT 中的函数。注意,并不是所有需要重定位的变量都在 GOT 中,例如:
1
2
static int a;
static int *d = &a;
由于 d 是静态初始化,即装载时修改它的初始值,而不是在运行时通过指令赋值,所以 b 也位于重定位表 .rela.dyn 中:
1
2
3
4
5
6
7
8
9
10
11
$ readelf -r libpic.so
Relocation section '.rela.dyn' at offset 0x4d0 contains 12 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000004008 000000000008 R_X86_64_RELATIVE 4018
...
$ readelf -s libpic.so
Symbol table '.symtab' contains 32 entries:
Num: Value Size Type Bind Vis Ndx Name
10: 0000000000004018 4 OBJECT LOCAL DEFAULT 23 a
11: 0000000000004008 8 OBJECT LOCAL DEFAULT 22 d
装载时重定位同样在地址无关的可执行文件中有所使用。要让可执行文件支持任意地址装载,使用如下命令:
1
gcc -fPIE -pie -o exe exe.c
像变量 d 使用朴素的装载时重定位,其他情况则使用 PIC 技术中的 GOT 或 GOT.PLT。
回看装载时重定位
在 x64 架构上,想要让共享对象或可执行文件被装载到任意地址,前提是开启 PIC 技术。重定位情况如下:
- 引用静态变量和静态函数:使用
rip + offset的方式访问,不需要重定位。 - 引用静态变量的地址:采用朴素的装载时重定位,直接修改指令或数据初始值。
- 全局变量:在可执行文件中,变量声明需要重定位。在共享库中,由于全局符号介入机制存在,变量定义也需要重定位。重定位信息位于
.rela.dyn中,重定位需要修改.got表项。 - 全局函数:在可执行文件中,函数声明需要重定位。在共享库中,由于全局符号介入机制存在,函数定义也需要重定位。
- 未开启 PLT:重定位信息位于
.rela.dyn中,重定位需要修改.got表项。 - 开启 PLT:重定位信息位于
.rela.plt中,重定位需要修改.got.plt表项。
- 未开启 PLT:重定位信息位于
Comments